
This page describes how you should structure your SourceSafe projects or TFS folders so that they fit into the mind-set of AbaPerls. There are two "levels" in this structure: the upper level with version-directories. for the subsystems and the lower level, the AbaPerls SQL Directory Structure, which is a foundation for the AbaPerls tools that load SQL objects.
It's common across file systems and version-control systems to have a hierarchy where there is a root container, and a container can include items as well other containers, which in their turn may contain other items and containers. It is also fairly common to call the non-container items files. On the other hand, there is not a unified name for the containers. In VMS and Unix they are called directories. Windows tend to favour the term folder but it uses directory as well, particularly on command-line level. In SourceSafe they are called projects. In TFS, the root container is called team-project collection and the containers on the next level are known as team projects, and then from the second level down they are called folders.
AbaPerls needs to refer to such hierarchies, both on disk and in version-control, and AbaPerls uses the same model for both. To get a consistent terminology, AbaPerls always uses the term directory for such a container, not matter it is in the file system, in SourceSafe or in TFS.
A subsystem is a component, module or similar that is part of your system. Since AbaPerls mainly focuses on SQL code, AbaPerls is not so concerned whether your subsystem also results in a DLL, an executable or something else. For AbaPerls a subsystem is most of all a module within a database.
As a simple example, take an order system with three basic concepts: customers, products and orders. Then there is an optional component for automatic ordering from suppliers when stocks are running low which requires gateways to communicate with the systems of the various suppliers. There might be other components for accounting etc.
Not all customers who buy this system need all these components, and there are also different teams working with the development of the various components. Still the optional components are heavily dependent on the tables and stored procedures for the basic concepts, so they need to be in the same database. Thus, one way to partition the database is to have one subsystem that includes the basic concepts. The component for automatic ordering would be another subsystem. All the gateways would be subsystems of their own (because which gateways you install is site-dependent). The accounting component would be yet another subsystem etc.
Typically you define which subsystems your system consists of in a system-definition file; this file defines their name and location. Different databases may have different configurations; that could be because different customers have different functionality, or that your system uses multiple databases. For each configuration you have a config-file that defines which subsystem that are part of that configuration. In a database, you find a list of the installed subsystems in the table abasubsystems – provided that you have installed the subsystem ABAPERLS with the AbaPerls system tables. The config-files can refer to the system-definition file to ensure that subsystems are consistently named.
A
subsystem may or may not have versions. Most commonly, it has. Versions and
subsystems can be arranged in different ways. You can have a top directory for the
subsystem and a subdirectory for each version as illustrated by the picture to
the left. Or you can have a top
directory for each version, and then have a subdirectory for each subsystem as
illustrated by the picture to the right.
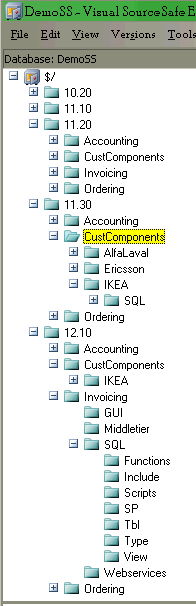
Let's study these pictures in little more details. If we start with the picture to the right, we see in total six subsystems, ACCOUNTING, INVOICING, ORDERING, ALPHALAVAL, ERICSSON and IKEA. (While the directory names in SourceSafe and TFS are in mixed case, subsystem names in AbaPerls are always uppercase only.) In this imaginary product, the first three are standard components, and then there are customer-specific adaptations, and they are gathered together under the node CustComponents. There is no requirement to do this, but the picture serves to illustrate that you can have subsystems on any level.
You may notice that in 11.30 there is no Invoicing folder, despite there is one in 11.20 and 12.10. This could because there was no development with invoicing in 11.30, why a leg for this component never was created in 11.30. Likewise, it seems that there is no development for ALPHA Laval and Ericsson in 12.10, at least not yet. It would be possible to create a directory in 12.10 for, say, Ericsson. This could be done manually through the SourceSafe GUI, or more easily (and better) with the AbaPerls tool NEWSUBSYSVER. That is, there is no requirement that all subsystems have the same version.
As for the version numbers, they are on the form Major.Middle where Middle typically always have two digits, whereas Major has as many digits needed. (But if you ever reach three digits, you are probably cranking out a wee bit too many versions.)
The Invoicing directory is expanded, and we see four subdirectories which each seem to hold components on different layers in the application. In this picture, the directories GUI, Middletier and Webservices are just mock-ups. What interests AbaPerls is the SQL directory where all SQL resides, and we will return to this directory in just a second.
But let's first look at the picture to the right. In this example from TFS, there is a team project which includes three different subsystems. First you see the AbaPerls system itself, and in AbaPerls there are no version directories. Blank test and Kati are two other subsystems (whereas BuildProcessTemplates is something that TFS adds on its own initiative.) The KATI subsystem is expanded, and you can see a number of version directories; the model here is subsystem-before-version. The two first versions are 1.0 and 2.0 – these versions are very old – normally, they would be 1.00 and 2.00. The node for version 2.63 is expanded, and the KATI subsystem consists of SQL files only, and they are collection in the SQL directory which has a number of subdirectories which you see on the right. We will return to them later.
When would you use version-before-subsystem and when would you use subsystem-before-version? If you have a product that has a single subsystem beside AbaPerls, subsystem-before-version is a natural choice, but if you have a system like AbaSec which consists of many subsystems, version-before-subsystem is easier to work with, and some features in AbaPerls are designed from the perspective that subsystems are collected under a common version directive. Note that you can still mix. If you have a generic component which does not integrate closely with the rest of the system, it could be managed separately with subsystem-before-version. (Or be without version at all like AbaPerls.)
In the version-before-subsystem example above, not all subsystems appear in all versions, but observe that this example is from SourceSafe where it would be fairly expensive to have projects for all subsystem in all versions even if there are no changes in them. In TFS creating branches is a lot less expensive, and it makes more sense when you start a new version to clone the entire version hierarchy. Particularly, this makes the system-definition file easier to maintain, as it can be remain unchanged between versions as long as you don't add or remove subsystems. If some subsystems are only in some versions, you need to include full paths in your sysdef-file and keep it updated.
A few TFS-specific notes: In the example, there is a team project with three subsystems. If your system is a single subsystem, it would be reasonable to have the team project as the main directory for the subsystem, with the version directories directly below the team project. However, if you have version-before-subsystem, it is not likely to be a good idea to have one team project for each version, given the mind-set of TFS. In this case you should have the versions two-levels down from the root $/.
As you can see in the figure, some of the version directories for KATI are regular folders, whereas others are branches. As far as AbaPerls is concerned, this has no importance. When you create new versions with NEWSUBSYSVER, they will appear as branches. (The reason that 1.0 to 2.61 are folders is because the subsystems in the screen-shot originally were converted from SourceSafe.)
As I mentioned, the SQL directory is what really interests AbaPerls. The SQL directory is the root for the AbaPerls Directory Structure, detailed below. The name of the directory must be SQL – if it's called something else, AbaPerls couldn't not be bothered.
On the other hand, AbaPerls permits some flexibility of where the SQL directory is located. In the examples above, the SQL directories are located directly below the version directory or the subsystem directory. But it is perfectly permissible to have some thing like $/12.10/Ordering/Database/SQL. You can even have more than one, for instance $/12.10/Ordering/LiveDB/SQL and $/12.10/Ordering/ArchiveDB/SQL. Why you would do this? In this example, the names indicate that the SQL code goes into different databases. If you would put these two directories in the same database, they would really be two subsystems.
While you can label your files any way you like, AbaPerls has a standard format for labels. If you adhere to this format, the update scripts generated by DBUPDGEN can verify that they are in sync with the database they are about to update. For instance, assume that you invent your own private format and use the labels Alpha, Beta, Gamma and Delta. You first build the database with DBBUILD from the Alpha label. Then you create one update script to take you from Alpha to Beta, one for Beta to Gamma and one from Gamma to Delta. With this scheme, there is nothing to alarm you if mistakenly run the Gamma-Delta script on a database which is in level Beta.
This is different if you stick to the AbaPerls label format LetterMajor.Middle.Minor. Examples of such labels are L11.30.0050, M10.20.1050 and A1.1.1. Major.Middle should agree with the version directory, whereas Minor is a number that you assign to the label. Each new label should have a higher number for Middle than the previous label. Thus, assume you build a database with label L11.30.0050 for a certain subsystem. Later you try to run an update script to upgrade the database from L11.30.0100 to L11.30.0150, AbaPerls would detect that you are out of the sync. The same would happen if you tried to run a script which starts at L11.20.0050 or L12.10.0050. On the other hand, AbaPerls would permit you to run a script that starts at L11.30.0030, as long as it takes the database beyond L11.30.0050. (Because it is assumed that the changes from L11.30.0030 to L11.30.0050 are re-runnable.)
There is a special convention to permit you to move from one version to another. When you create a new version with NEWSUBSYSVER, AbaPerls labels the old version with a label where Minor = 1000, and the new version gets a label where Minor is 0001. Thus, if the database is on L11.30.1000, you can run an update script that starts at L12.10.0001. Minor in the database does not have to be 1000 – anything that is ≥ 1000 is acceptable. The assumption is that all changes that are beyond the Major.Middle.1000 label are also in the later version. Depending how check-ins and merges have been done this is necessarily not true, but this is as good as it goes.
The convention is to have two digits in Middle and four digits in Minor, but leading zeroes are not significant. L11.10.30; L11.010.030 and L11.10.0030 are equal as far as AbaPerls is concerned. When it comes to any distinction between Major and Middle, currently there isn't any. That is, going from 11.30 to 12.10 is no different than going from 12.10 to 12.11. Nor is there any requirement that you use numbers without gaps. If you make bold changes in your product, feel free to move from 4.50 to 10.00.
You may ask what the meaning of Letter is and the answer is that it means – nothing. The letter was introduced to cope with idiosyncrasies in SourceSafe (a label like 11.30.0040 could be interpreted as a time value). For AbaPerls L11.30.0030, K11.30.0030 and M11.30.0030 are all the same label. Note that it is always a single letter; a label like BL11.30.0050 is not an AbaPerls label but just "a label".
Rather than creating labels manually, you should use the tool NEWLABEL which checks that you don't violate any of the rules for AbaPerls labels. NEWLABEL can also compute the next label for you.
As you have seen the rules for the path down to the SQL directory are loose and flexible. But once you are there it is a strict régime. In the figure from TFS above, you can see that the SQL directory contains eight directories and one file, and these items are not named out of thin air. All these names are recognised by AbaPerls and constitute the AbaPerls SQL Directory Structure. AbaPerls maps various types of SQL objects to different file extensions, and each extension in its turn maps to a certain directory. This mapping is essential to the AbaPerls file-lookup order that several tools rely on. AbaPerls applies this mapping both on disk and in version-control.
This picture illustrates the structure, and which file extension that goes into which directory.

These in total twelve directory and file names have a special meaning to AbaPerls and they should be placed as indicated as above. That is, SQL should be the root, and the other nine directories should be directly below. You are not required to have all of them; for instance you would not create any View directory, if you don't have any views. But if you have views, they should be stored in .view files, residing the View directory. If you put them elsewhere, AbaPerls will not find them. You can have files with other extensions than the ones above, but if you feed them to AbaPerls will just return a blank stare and not understand what you are talking about. The directory names are not case-sensitive; you can use view, View and VIEW all alike.
And it does not stop there. AbaPerls is also very strict with the correlation
between the name of the files, and the names of the objects defined in the file.
If you have a view named MyView, it should be defined in a file
MyView.View, and this file should define no other
objects. The extension is not case-sensitive, but the name is. Thus,
myview.View or MYVIEW.View
will not do. But MyView.view or
MyView.VIEW will. For some, but not all, type of objects you can force a deviation with
the ‑force option, which is good when you want to test a parallel version of a
stored procedure. The exact mapping rules are detailed below, directory for
directory. When nothing is said, you cannot use ‑force to override the rule.
And while somewhat beyond the topic for this page, it is worth mentioning that AbaPerls disallows a name to appear in more than one subsystem. That is, if you create some_sp in subsystem A, and you then try to create some_sp in subsystem B as well, AbaPerls will give you an error. (This can be overridden only in an update script generated by DBUPDGEN, see the section Suppressing the Name-Clash Check.) For some file types, the file itself is the object for AbaPerls. In this case, the same file name can appear in multiple subsystems.
You can create other directories or files in the SQL directory with other names than the eleven above, but they will not have any meaning to AbaPerls, and AbaPerls will ignore them entirely. You should avoid using these names for directories outside the SQL structure, as you could be victim to some unexpected surprises if you do.
The ten subdirectories can have subdirectories in their turn. This permits you to group stored procedures which has some common characteristics, but which are not special enough to warrant a subsystem on their own. Say for instance that you create a subdirectory Minis in the SP directory and there is a stored procedure mini_initialise_sp. When you talk to AbaPerls, you refer to the file as Mini/mini_initialise_sp.sp. Note that if you also have a mini_initialise_sp.sp directly under SP, AbaPerls will not detect the clash, and it will be willy-nilly which file that is loaded.
If a subdirectory name ends in an exclamation mark (!) this has a special meaning. In this case, AbaPerls assumes that the subdirectory name is the name of a subsystem (minus the exclamation mark), and AbaPerls only load the file if that subsystem is installed in the database. Say that you have a subsystem that consists of API procedures that your customers can use. This API includes procedures that access tables in the ACCOUNTING subsystem, but not all customers have this subsystem. You can still keep these procedures in the API subsystem by putting them in the ACCOUNTING! subdirectory. For instance ACCOUNTING!/api_get_todays_bookings_sp.sp.
Here is a description of what all directories are supposed to contain.
Beside the ten main subdirectories SQL is the home for one file grant.template. This file specifies the permissions that are to be granted or denied on the objects in the database. There can also be a grant.template in the version directory. The format of these files is described on the page for the AbaPerls file-loading process.
The Message directory includes files with the extensions .sql, .syno and .postsql. When you build an empty database with DBBUILD, the .sql files are loaded before any other file in the subsystem whereas the .postsql files are loaded after all other files.
In an .sql file you typically create basic objects that AbaPerls does not track specifically. Some examples are users, roles and user-defined messages.
In .syno files you define synonyms. See further the page Using Synonyms for details. You can only use .syno files if the ABAPERLS subsystem is installed in the database.
In .ddltri files you define DDL triggers on database level. (AbaPerls does not support server-level triggers.) AbaPerls comes with two DDL triggers itself to prevent casual modification of objects loaded with AbaPerls from outside Abaperls. See the documentation of the table abaddltribypasslog for details. The name of the DDL trigger must agree with the file name.
In .postsql files you put things that require objects in the subsystem to be present, for instance binding a Service Broker queue to a stored procedure, or the load of start-up data.
In the MESSAGE directory, there is no enforcement that file names agree with object names and AbaPerls does not track the object within the files; rather each file counts as a object on its own.
The misleading directory name stems from the fact that originally this directory was used only for user-defined messages.
The Include directory holds files with extension .sqlinc. These files are included by other files with the Preppis preprocessor. The main purpose of include-files is to share temp tables between stored procedure and/or functions, but that does not exclude other uses for include files. See further about include-files on the Preppis page. .sqlinc files do not define any objects, but the files are objects of their own.
The Assemblies directory holds files related to the CLR. Up to six different extensions can appear in this directory:
| assembly.assem | The main file for the assembly with the CREATE ASSEMBLY statement. |
| assembly.dll | The file that holds the compiled and linked DLL. |
| assembly.cs | Source for the assembly in C#. |
| assembly.vb | Source for the assembly in Visual Basic .Net. |
| assembly.safedll | A dummy version of a privileged assembly that can be loaded with PERMISSION_SET = SAFE. |
| keyname.snk | A key pair that is used to sign an assembly compiled from a C# or VB source. |
For a given assembly there is always an .assem file and one file with one of the extensions .dll, .cs or .vb. Optionally there can also be a .safedll file for the assembly. The .snk files are not tied to an assembly.
For more details on using CLR assemblies with AbaPerls, see the page Using the CLR with AbaPerls.
The Type directory holds files with the extensions .xmlsc, .typ, .seq and .tbltyp.
.xmlsc files holds definitions of XML schemas with the command CREATE XML SCHEMA DEFINITION. The name of the schema collection must agree with the file, or you will get an error message. This is not overridable.
A .typ file defines a
user-defined scalar datatype with CREATE TYPE or EXEC sp_addtype.
The name of the type must agree with the name of the file. There is no support
for CLR UDT types.
A .typ file can optionally also define a default with CREATE DEFAULT and
bind the default to the type with EXEC sp_bindefault. You form the
name of the default by adding _default as a suffix on the type name.
Likewise a .typ file can define a rule with CREATE RULE and bind
the rule to the type and EXEC sp_bindrule. You form the name for a rule by
adding _rule to the type name. In case you wonder, AbaPerls defines no space for rules and defaults
that are bound directly to columns. Nor is there any point in it, since you should
use CHECK and DEFAULT constraints instead.
(Microsoft has deprecated rules and defaults for many years, but they have not
yet presented any reasonable alternative for types.)
One class of type names are special: these are the type names ending in _moduser. DBUPDGEN assumes that such a type has a rule bound to it, and that this rule requires the contents of a column with this type to agree with the current user. See further about table-updates on the DBUPDGEN page.
Files of the type .seq are for the definition of sequences with the statement CREATE SEQUENCE. The name of the sequence must agree with the file name, or there will be an error message. This is not overridable.
You use .tbltyp files to define table types with CREATE TYPE AS TABLE. The name of the table type must agree with the file name.
Because it is not possible to change a table type that is in use with less than dropping all dependent objects, a .tbltyp file should have a $USEDBY line for each stored procedure or function that uses the type as parameter:
$USEDBY my_stored_sp.sp $USERBY OTHERSUBSYSTEM!some_funky_func.sqlfun
Likewise must the procedures and function that uses the type as parameter include a $DEPENDSON directive:
$DEPENDSON some_tabletype.tbltyp
This permits DBUPDGEN to automatically add all dependent procedures and functions when the type is changed.
You can also define private XML schemas and table types in files that defined stored procedures and user-defined functions, see the SP section for details.
The ServiceBroker directory includes files with the extensions .mty and .sb. The .mty files holds definitions of message types with the command CREATE MESSAGE TYPE. The name of the type must agree with the file name. .mty files are intended for general message types that are used in more than Service Broker file.
The .sb files hold definitions of Service Broker objects through the commands CREATE MESSAGE TYPE (which can appear in both .mty and .sb files), CREATE CONTRACT, CREATE QUEUE, CREATE SERVICE and CREATE BROKER PRIORITY. For .sb files, there is no requirement that object names must match the file name; rather a file includes a number of objects that all are part of the same Service Broker implementation. See further the page Service Broker in AbaPerls.
The Tbl directory contains files for tables. There can be up to six files for one single table:
| tablename.tbl | The table definition with CREATE TABLE . |
| tablename.fkey | All foreign-key constraints for the table. |
| tablename.tri | All triggers for the table. |
| tablename.ix | Indexes and statistics for the table that are not PRIMARY KEY or UNIQUE constraints. |
| tablename.ins | INSERT-files that loads the table with predefined data. |
| tablename.xls(x) | An Excel workbook from which you create tablename.ins with INSFILGEN. |
| tablename.srcdata | An XML file from which INSFILGEN creates the Excel book. |
tablename.tbl normally contains a single statement: CREATE TABLE which should include the definition of any PRIMARY KEY and UNIQUE constraints the table has. (A table should normally have a primary key; not defining one would be an exceptional thing to do.) The .tbl file is also the preferred place to put CHECK and DEFAULT constraints. You should not put FOREIGN KEY constraints in this file. AbaPerls thinks that you should name all your constraints, and unnamed constraints will render you an error or a warning depending on which tool you use.
Starting with SQL 2014, SQL Server permits you to define indexes in the CREATE TABLE statement, but AbaPerls does not support this and you will get an error message if you try. (There is no good reason for this; consider it a limitation.)
If the name of the table does not agree with the file (case-sensitive), AbaPerls issues an error message when you load the file.
Beside the CREATE TABLE statement, you can include commands to control physical storage properties. More precisely this is
sp_tableoption for controlling properties such as text in row. Note that
should include the table name; AbaPerls will added. For more details, see the page Storage Settings for Tables and Indexes. As for other commands, AbaPerls may or may not let you get away with it, but please understand that it is not supported, and it could fail in a later release of AbaPerls.
tablename.tri includes triggers for the table. In difference to stored procedures, you don't have one file per trigger, but you gather the triggers for a table in one file, per subsystem. That is, say that subsystem ALPHA includes mytable.tbl as well as some triggers in mytables.tri.. Say now that subsystem BETA, which refers to ALPHA, wants to add its own validation or cascading update to mytable. It is perfectly legal for BETA to add triggers in its own mytables.tri. There are couple of caveats associated with this, whereof some are related to SQL Server and others to AbaPerls:$DEPENDSON ALPHA!mytable.tbland mytable.tbl in ALPHA must include this line:
$USEDBY BETA!mytable.truIf you make a change to mytable.tbl such that the table must be reloaded all trigger files must be reloaded as well. DBUPDGEN understands to add mytable.tri from ALPHA on its own, but it needs the $USEDBY to be aware of that there is a mytable.tri in BETA, so that this file can be added to the update script for ALPHA. (If the $DEPENDSON would be missing from mytable.tri in BETA, DBUPDGEN will add the file to all update scripts generated for BETA, as this was the old behaviour before the $DEPENDSON directive was introduced.
If the name of the table does not agree with the file, AbaPerls issues an error message when you load the file.
tablename.fkey should include one ALTER TABLE statement for the table that adds all FOREIGN KEY constraints for the table. You may also opt to put CHECK and DEFAULT constraints in this file. All constraints in the .fkey file must be named. With foreign keys in files of their own, DBBUILD can create the tables without worrying about dependency order. (Why would you put CHECK and DEFAULT constraints in the .fkey file? If you need to change them, re-loading an .fkey file is a much smaller affair than re-loading a .tbl file. See more on the DBUPDGEN page for this.)
Just as with triggers, a referring subsystem can add its own foreign keys to a table in a lower subsystem, although this may rarely be practically useful. The requirement to use $DEPENDSON in the .fkey file and $USEDBY in the .tbl file applies here as well.
If the name of the table does not agree with the file, AbaPerls issues an error message when you load the file.
tablename.ix should include all indexes for the table (except for PRIMARY KEY and UNIQUE constraints). This is also where you put any CREATE STATISTICS statements for the table. A good advice is to put the clustered index first in the file, in the case where none of the PRIMARY KEY and UNIQUE constraints are clustered, as SQL Server rebuilds all non-clustered indexes when you create or drop a clustered index.
Beware that AbaPerls does not fully support special indexes such XML indexes, fulltext indexes or spatial indexes. Nor is there support for columnstore indexes. Filtered indexes and included columns are supported.
As for triggers, a referring subsystem can add its own indexes to a table in an inner subsystem. As with triggers, you need to use $DEPENDSON and $USEDBY in this cas.
If the name of the table does not agree with the file, AbaPerls issues an error message when you load the file.
tablename.ins includes statements to maintain predefined data for the table. There may be several reasons why you want to have such a file. The most common case is data on which the system depends, for instance transaction types or system parameters. Keep in mind that when you write an INSERT-file, that it should be possible to run the file more than once, which rules out bare INSERT statements in most cases. Typically such a file consists of a number of stored-procedure calls. The page for INSFILGEN includes a good example of an INSERT-file.
A referring subsystem can add its own INSERT-file for a table, and this is often very useful. This works somewhat differently from triggers, foreign keys and indexes. A default table-update generated by DBUPDGEN copies existing data. Therefore, an update script for a referring subsystem will only include the INSERT-file if the file has actually changed. For INSERT-files, you don't need to add $DEPENDSON to the table file, since the data is assumed to be retained in case of a table change.
For INSERT-files, AbaPerls does not perform any checks that file name agrees with any object name.
tablename.xls(x) is used as input to INSFILGEN to generate the INSERT-file. Many tables with predefined data are small; maybe only 3-4 columns and some 10-15 rows. For them a plain INSERT-file with calls to a stored procedure is fairly simple to manage. But if you have 30 columns and 300 rows to insert, and what to insert depends on $IFDEF directives, then a plain file is getting very cumbersome to maintain. Therefore you can define the predefined data in an Excel workbook and generate the .ins file with INSFILGEN.
tablename.srcdata is also used as input to INSFILGEN, but in this case INSFILGEN generates an Excel book from which you can generate an INSERT-file. While the Excel files make it easy to maintain the data to insert, they don't work well with version control and particularly for merging since they are binary. (You can save Excel books as XML files, but merging these files has proven to be difficult.) Therefore INSFILGEN offers the .srcdata format as a means to put the source data for INSERT files under version control in a text format, while still offering the easiness of editing that Excel gives you. For more information on whether to work with .srcdata files or only Excel books, see the topic for INSFILGEN.
not-a-table.ins. Sometimes when you build an empty database with DBBUILD you may need to load data in some tables before any you load any other tables, because other INSERT-files refers to this data. In this case you can use a "fake" INSERT-file, that is, an INSERT-file where the name does not coincide with a table. For instance, in AbaSec, there is a file aaaa-bootstrap.ins. (DBBUILD loads files in alphabetic order, so this INSERT-file is run first.) Likewise, you could have a file zzzz-wrapup.ins that performs some commands that rely on that all predefined data is present.
The View directory contains files for views. There can be up to three files for one view:
| viewname.view | The table definition with CREATE VIEW . |
| viewname.vtri | All triggers for the view. |
| viewname.vix | Indexes and statistics for the view. |
For all files, AbaPerls emits an error message if the name of the file does not agree with the view. As for tables, you have all triggers and indexes for the view in the same file.
In difference to tables, AbaPerls does not really support that a referring subsystem adds its own triggers or indexes for a view. Since you can only have INSTEAD OF triggers on views, and SQL Server only permits one INSTEAD OF trigger per action, it would not be very meaningful anyway.)
If the view is defined WITH SCHEMABINDING, the .view file must have $DEPENDSON directives to all objects that the view refers to, since the view must be dropped it these objects are changed.
The SP directory contains files with the extension .sp.
Each .sp file defines one stored procedure and the name of the procedure
should agree with the file name, or else AbaPerls will give you an error message
when you load the file. When you load the file with ABASQL, you can use
the ‑force option to load a procedure with a different name from the file. This
is useful when creating temporary debug versions in test or production systems.
Beside the CREATE PROCEDURE statement itself, an .sp file may include creation of temp tables (preferably through include-files) that the stored procedure refers to, but does not create itself. Very occasionally you may include GRANT statements as discussed on the file-loading page. You should never include explicit code for dropping the stored procedure; AbaPerls takes care of this.
An .sp file may also include private definitions of table types or XML schema collections used only in this procedure. The name of a private type for a stored procedure consists of the name of the stored procedure enclosed in $ characters, and optionally you can have a suffix. When you have a client-side component that sends data through a TVP to a stored procedure, it would be impractical for several reasons having to define the table type in a separate .tbltyp file. Furthermore, if you need to change the type to add one more column to pass to the procedure, that would require you to change a .tbltyp file, and the buildmaster must in this case certify that no other file is affected. With private types, this is not an issue, AbaPerls does not permit any other procedure to use the type.
Here is an example of using a private type:
CREATE TYPE [$tbltyp_dbltest_sp$] AS TABLE (a int NOT NULL PRIMARY KEY,
a2 smalldatetime NULL,
b int NOT NULL)
CREATE TYPE [$tbltyp_dbltest_sp$typ2] AS TABLE (x tinyint NOT NULL PRIMARY KEY,
y datetime NULL,
z varchar(23) NOT NULL)
go
CREATE PROCEDURE tbltyp_dbltest_sp @tbl1 [$tbltyp_dbltest_sp$] READONLY,
@tbl2 [$tbltyp_dbltest_sp$typ2] READONLY AS
The example illustrates why you would use a suffix in the type name: your procedure accepts two table-valued parameters. Note that you must put the name of the private types in brackets; T‑SQL does not permit leading $ in identifiers.
Note that if you want to use a table-value parameter to pass data from one procedure to another, you cannot use a private type, but you must define the type in a .tbltyp file. Private types are intended to be used when you want to sent one or more sets of data from a client to SQL Server.
The Functions directory holds files with the extension .sqlfun which contains
user-defined functions created with CREATE FUNCTION or CREATE AGGREGATE. The same notes as for .sp files apply. That is, you can override the name check with
ABASQL if you use ‑force; you can use $INCLUDE files, and you can use private
types.
AbaPerls does not make any distinction between the three types of functions that SQL Server defines (scalar functions, inline table functions and multi-statement table functions), but regard them all the same and also lumps user-defined aggregates in this group.
If a function refers to another function, you should add a $REQUIRE directive for that function to force AbaPerls to load the other function first. Else AbaPerls may give you an error about the missing function. (AbaPerls checks that you do not call undefined functions.)
The Scripts directory is somewhat different from the other directories, because AbaPerls does not make the same rigid binding of extensions to Scripts as the other directory. Then again, you would never load any file from this directory with ABASQL or DBBUILD. Scripts is where you put the update scripts generated by the DBUPDGEN with or without manual improvements, both on disk and in version-control. In Scripts can also have various Perl, .bat or .sql files that you want to have at hand, but not be part of the build process.
Nevertheless, the name is reserved by AbaPerls, and the tools SSGREP and SSREPLACE ignores the path sql/scripts.
Copyright © 1996-2021,
Erland Sommarskog SQL-Konsult AB.
All rights reserved. AbaPerls is available under
Perl Artistic License
This page last updated 21-12-29 17:23