Understanding Performance Mysteries
An SQL text by Erland Sommarskog, SQL Server MVP. Last revision: 2026-02-20.
Copyright applies to this text. See here for font conventions used in this article.
This article is also available in Russian, translated by Dima Piliugin.
When I read various forums about SQL Server, I frequently see questions from deeply mystified posters. They have identified a slow query or slow stored procedure in their application. They take the SQL batch from the application and run it in SQL Server Management Studio (SSMS) to analyse it, only to find that the response is instantaneous. At this point they are inclined to think that SQL Server is all about magic. A similar mystery is when a developer has extracted a query in his stored procedure to run it stand-alone only to find that it runs much faster – or much slower – than inside the procedure.
No, SQL Server is not about magic. But if you don't have a good understanding of how SQL Server compiles queries and maintains its plan cache, it may seem so. Furthermore, there are some unfortunate combinations of different defaults in different environments that contribute to this confusion. In this article, I will try to straighten out why you get this seemingly inconsistent behaviour. I explain how SQL Server compiles a stored procedure, what parameter sniffing is and why it is part of the equation in the vast majority of these confusing situations. I explain how SQL Server uses the cache, and why there may be multiple entries for a procedure in the cache. Once you have come this far, you will understand how come the query runs so much faster in SSMS.
To understand how to address that performance problem in your application, you need to read on. I first make a short break from the theme of parameter sniffing to discuss a few situations where there are other reasons for the difference in performance. This is followed by two chapters on how to deal with performance problems where parameter sniffing is involved. The first is about gathering information. In the second chapter I discuss some scenarios – both real-world situations I have encountered and more generic ones – and possible solutions. Next comes a chapter where I discuss how dynamic SQL is compiled and interacts with the plan cache and why there are more reasons you may experience differences in performance between SSMS and the application with dynamic SQL. In the last full chapter I look at how you can use Query Store, a feature that was introduced in SQL 2016 for your troubleshooting. There are two more chapters, which are more like appendixes. The first discusses a feature known as PSP optimisation, introduced in SQL 2022, which is an attempt to reduce the performance impact of parameter sniffing. The second appendix discusses how temp-table caching can have effects similar to those of parameter sniffing. At the end, there is a section with links to Microsoft white papers and similar documents in this area.
Table of Contents
How SQL Server Compiles a Stored Procedure
How SQL Server Generates the Query Plan
Putting the Query Plan into the Cache
Different Plans for Different Settings
The Effects of Statement Recompile
Statement Recompile and Table Variables and Table-Valued Parameters
It's Not Always Parameter Sniffing...
Replacing Variables and Parameters
Getting Information to Solve Parameter-Sniffing Problems
Getting the Query Plans and Parameters with Management Studio
Getting the Query Plans and Parameters Directly from the Plan Cache
Getting the Most Recent Actual Execution Plan
Getting Query Plans and Parameters from a Trace
Getting Table and Index Definitions
Finding Information About Statistics
Examples of How to Fix Parameter-Sniffing Issues
The Case of the Application Cache
The Query Text is the Hash Key
The Significance of the Default Schema
Running Application Queries in SSMS
Finding Sniffed Parameter Values
Forcing Plans with Query Store
Setting Hints through Query Store
Appendix A: PSP Optimisation in SQL 2022
The essence of this article applies to all versions of SQL Server from SQL 2005 and on. The article includes several queries to inspect the plan cache. Beware that to run these queries you need to have the server-level permission VIEW SERVER PERFORMANCE STATE. (This permission was introduced in SQL 2022. On earlier versions, you will need the permissions VIEW SERVER STATE.) When a feature was introduced in a certain version or is only available in some editions of SQL Server, I try to mention this. On the other hand, I don't explicitly mention whether a certain feature or behaviour is available on Azure SQL Database or Azure SQL Managed Instance. Since these platforms are cutting-edge, you can assume that they support everything I discuss in this article. However, the names of some DMVs may be different on Azure SQL Database.
For the examples in this article, I use the Northwind sample database. This is an old demo database from Microsoft, which you find in the file Northwind.sql. (I have modified the original version to replace legacy LOB types with MAX types.)
This is not a beginner-level article, but I assume that the reader has a working experience of SQL programming. You don't need to have any prior experience of performance tuning, but it certainly helps if you have looked a little at query plans and if you have some basic knowledge of indexes, that is even better. I will not explain the basics in depth, as my focus is a little beyond that point. This article will not teach you everything about performance tuning, but at least it will be a start.
The majority of the screenshots and output in this article were collected with SSMS 18.8 against an instance of SQL Server running SQL 2019 CU8. If you use a different version of SSMS and/or SQL Server you may see slightly different results. I would however recommend that you use the most recent version of SSMS which you can download here.
In this chapter we will look at how SQL Server compiles a stored procedure and uses the plan cache. If your application does not use stored procedures, but submits SQL statements directly, most of what I say in this chapter is still applicable. But there are further complications with dynamic SQL, and since the facts about stored procedures are confusing enough, I have deferred the discussion on dynamic SQL to a separate chapter.
That may seem like a silly question, but the question I am getting at is: What objects have query plans on their own? SQL Server builds query plans for these types of objects:
With a more general and stringent terminology I should talk about modules, but since stored procedures is by far the most widely used type of module, I prefer to talk about stored procedures to keep it simple.
For other types of objects than the four listed above, SQL Server does not build query plans. Specifically, SQL Server does not create query plans for views and inline-table functions. Queries like:
SELECT abc, def FROM myview SELECT a, b, c FROM mytablefunc(9)
are no different from ad-hoc queries that access the tables directly. When compiling the query, SQL Server expands the view/function into the query, and the optimizer works with the expanded query text.
There is one more thing we need to understand about what constitutes a stored procedure. Say that you have two procedures, where the outer calls the inner one:
CREATE PROCECURE Outer_sp AS ... EXEC Inner_sp ...
I would guess most people think of Inner_sp as being independent from Outer_sp, and indeed it is. The execution plan for Outer_sp does not include the query plan for Inner_sp, only the invocation of it. However, there is a very similar situation where I've noticed that posters on SQL forums often have a different mental image, to wit dynamic SQL:
CREATE PROCEDURE Some_sp AS
DECLARE @sql nvarchar(MAX),
@params nvarchar(MAX)
SELECT @sql = 'SELECT ...'
...
EXEC sp_executesql @sql, @params, @par1, ...
It is important to understand that this is no different from nested stored procedures. The generated SQL string is not part of Some_sp, nor does it appear anywhere in the query plan for Some_sp, but it has a query plan and a cache entry of its own. This applies, no matter if the dynamic SQL is executed through EXEC() or sp_executesql.
Starting with SQL 2019, scalar user-defined functions have become a blurry case. In this version, Microsoft introduced inlining of scalar functions, which is a great improvement for performance. There is no specific syntax to make a scalar function inlined, but instead SQL Server decides on its own whether it is possible to inline a certain function. To confuse matters more, inlining does not happen in all contexts. For instance, if you have a computed column that calls a scalar UDF, inlining will not happen, even if the function as such qualifies for it. Thus, a scalar user-defined function may have a cache entry of its own, but you should first look at the plan for the query you are working with; you may find the logic for the function inside has been expanded into the plan. This is nothing we will discuss further in this article, but I wanted to mention it here to get our facts straight.
When you enter a stored procedure with CREATE PROCEDURE (or CREATE FUNCTION for a function or CREATE TRIGGER for a trigger), SQL Server verifies that the code is syntactically correct, and also checks that you do not refer to non-existing columns. (But if you refer to non-existing tables, it lets you get away with it, due to a misfeature known as deferred named resolution.) However, at this point SQL Server does not build any query plan, but merely stores the query text in the database.
It is not until a user executes the procedure, that SQL Server creates the plan. For each query, SQL Server looks at the distribution statistics it has collected about the data in the tables in the query. From this, it makes an estimate of what may be the best way to execute the query. This phase is known as optimisation. While the procedure is compiled in one go, each query is optimised on its own, and there is no attempt to analyse the flow of execution. This has a very important ramification: the optimizer has no idea about the run-time values of variables. However, it does know what values the user specified for the parameters to the procedure.
Consider the Orders table in the Northwind database, and these three procedures:
CREATE PROCEDURE List_orders_1 AS SELECT * FROM Orders WHERE OrderDate > '20000101' go CREATE PROCEDURE List_orders_2 @fromdate datetime AS SELECT * FROM Orders WHERE OrderDate > @fromdate go CREATE PROCEDURE List_orders_3 @fromdate datetime AS DECLARE @fromdate_copy datetime SELECT @fromdate_copy = @fromdate SELECT * FROM Orders WHERE OrderDate > @fromdate_copy go
Note: Using SELECT * in production code is bad practice. I use it in this article to keep the examples concise.
Then we execute the procedures in this way:
EXEC List_orders_1 EXEC List_orders_2 '20000101' EXEC List_orders_3 '20000101'
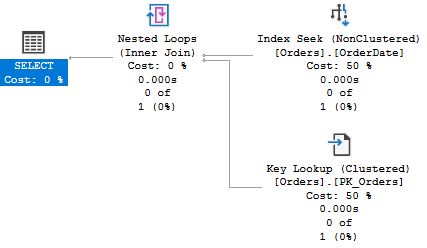
Before you run the procedures, enable Include Actual Execution Plan under the Query menu. (There is also a toolbar button and Ctrl-M is the normal keyboard shortcut.) If you look at the query plans for the procedures, you will see the first two procedures have identical plans:
That is, SQL Server seeks the index on OrderDate, and uses a key lookup to get the other data. The plan for the third execution is different:
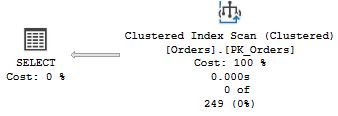
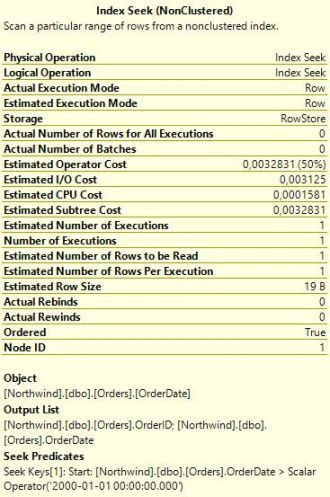
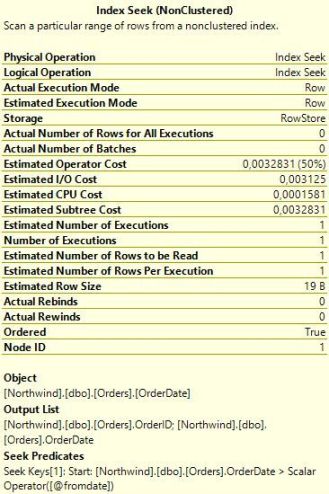
In this case, SQL Server scans the table. (Keep in mind that in a clustered index the leaf pages contain the data, so a clustered index scan and a table scan is essentially the the same thing.) Why this difference? To understand why the optimizer makes certain decisions, it is always a good idea to look at what estimates it is working with. If you hover with the mouse over the two Seek operators and the Scan operator, you will see the pop-ups similar to those below.
|
|
| List_orders_1 | List_orders_2 |

|
|
| List_orders_3 | |
The interesting element is Estimated Number of Rows Per Execution. For the first two procedures, SQL Server estimates that one row will be returned, but for List_orders_3, the estimate is 249 rows. This difference in estimates explains the different choice of plans. Index Seek + Key Lookup is a good strategy to return a smaller number of rows from a table. But when more rows match the seek criteria, the cost increases, and there is an increased likelihood that SQL Server will need to access the same data page more than once. In the extreme case where all rows are returned, a table scan is much more efficient than seek and lookup. With a scan, SQL Server has to read every data page exactly once, whereas with seek + key lookup, every page will be visited once for each row on the page. The Orders table in Northwind has 830 rows, and when SQL Server estimates that as many as 249 rows will be returned, it (rightly) concludes that the scan is the best choice.
Now we know why the optimizer arrives at different execution plans: because the estimates are different. But that only leads to the next question: why are the estimates different? That is the key topic of this article.
In the first procedure, the date is a constant, which means that the SQL Server only needs to consider exactly this case. It interrogates the statistics for the Orders table, which indicates that there are no rows with an OrderDate in the third millennium. (All orders in the Northwind database are from 1996 to 1998.) Since statistics are statistics, SQL Server cannot be sure that the query will return no rows at all, so it settles for an estimate of one single row.
In the case of List_orders_2, the query is against a variable, or more precisely a parameter. When performing the optimisation, SQL Server knows that the procedure was invoked with the value 2000-01-01. Since it does not perform any flow analysis, it can't say for sure whether the parameter will have this value when the query is executed. Nevertheless, it uses the input value to come up with an estimate, which is the same as for List_orders_1: one single row. This strategy of looking at the values of the input parameters when optimising a stored procedure is known as parameter sniffing.
In the last procedure, it's all different. The input value is copied to a
local variable, but when SQL Server builds the plan, it has no understanding of
this and says to itself I don't know what the value of this variable will
be. Because of this, it applies a standard assumption, which for an inequality
operation such as > is a 30 % hit-rate. 30 % of 830 is indeed 249.
Here is a variation of the theme:
CREATE PROCEDURE List_orders_4 @fromdate datetime = NULL AS
IF @fromdate IS NULL
SELECT @fromdate = '19900101'
SELECT * FROM Orders WHERE OrderDate > @fromdate
In this procedure, the parameter is optional, and if the user does not fill in the parameter, all orders are listed. Say that the user invokes the procedure as:
EXEC List_orders_4
The execution plan is identical to the plan for List_orders_1 and List_orders_2. That is, Index Seek + Key Lookup, despite
that all orders are returned. If you
look at the pop-up for the Index Seek operator, you will see that it is identical to the pop-up for List_orders_2 but in one regard, the actual number of rows.
When compiling the procedure, SQL Server
does not know that the value of @fromdate changes, but compiles the procedure
under the assumption that @fromdate has the value NULL. Since all comparisons with NULL yield
UNKNOWN, the query cannot return any rows at all, if @fromdate still
has this value at run-time. If SQL Server would take the input value as the final
truth, it could construct a plan with only a Constant Scan that does not access the table at all (run the query SELECT * FROM Orders WHERE OrderDate >
NULL to see an example of this). But SQL Server must generate a plan which
returns the correct result no matter what value @fromdate has at run-time. On
the other hand, there is no obligation to build a plan which is the best for all
values. Thus, since the assumption is that
no rows will be returned, SQL Server settles for the Index Seek. (The estimate is still that one row will be returned. This is
because SQL Server never uses an estimate of 0 rows.)
This is an example of when parameter sniffing backfires, and in this particular case it may be better to write the procedure in this way:
CREATE PROCEDURE List_orders_5 @fromdate datetime = NULL AS DECLARE @fromdate_copy datetime SELECT @fromdate_copy = coalesce(@fromdate, '19900101') SELECT * FROM Orders WHERE OrderDate > @fromdate_copy
With List_orders_5 you always get a Clustered Index Scan.
In this section, we have learned three very important things:
And there is a corollary of this: if you take out a query from a stored procedure and replace variables and parameters with constants, you now have quite a different query. More about this later.
Before we move on, a little more about what you can see in modern versions of SSMS. Here we looked at the popups to see the estimates and the actual values. However, if you look in the graphical plan you can see that below the operators it says things like 0 of 249. This means 0 actual rows of 249 estimated. Below is a detail from the plan for List_orders_4. When it says 830 of 1, this means that 830 rows were returned, but that the estimate was one single row.
This does not mean that in modern versions of SSMS you never need to look at the popups. There are more actual and estimated values that are worth looking at. For instance, I often compare Number of Executions with Estimated Number of Executions. But it is certainly handy to have the estimated and actual number of rows present directly in the graphic plan, as a big difference between the two is often part of the answer to why a query is slow, and we will look into this more later in this article.
If SQL Server would compile a stored procedure – that is, optimise and build a query plan – every time the procedure is executed, there is a big risk that SQL Server would crumble from all the CPU resources it would take. I immediately need to qualify this, because it is not true for all systems. In a big data warehouse where a handful of business analysts run complicated queries that take a minute on average to execute, there would be no damage if there was compilation every time – rather it could be beneficial. But in an OLTP database where plenty of users run stored procedures with short and simple queries, this concern is very much for real.
For this reason, SQL Server caches the query plan for a stored procedure, so when the next user runs the procedure, the compilation phase can be skipped, and execution can commence directly. The plan will stay in the cache, until some event forces the plan out of the cache. Examples of such events are:
If such an event occurs, a new query plan will be created the next time the procedure is executed. SQL Server will anew "sniff" the input parameters, and if the parameter values are different this time, the new query plan may be different from the previous plan.
There are other events that do not cause the entire procedure plan to be evicted from the cache, but which trigger recompilation of one or more individual statements in the procedure. The recompilation occurs the next time the statement is executed. This applies even if the event occurred after the procedure started executing. Here are examples of such events:
These lists are by no means exhaustive, but you should observe one thing which is not there: executing the procedure with different values for the input parameters from the original execution. That is, if the second invocation of List_orders_2 is:
EXEC List_orders_2 '19900101'
The execution will still use the index on OrderDate, despite that the query is now retrieving all orders. This leads to a very important observation: the parameter values of the first execution of the procedure have a huge impact for subsequent executions. If this first set of values for some reason is atypical, the cached plan may not be optimal for future executions. This is why parameter sniffing is such a big deal.
Note: for a complete list of what can cause plans to be flushed or statements to be recompiled, see the white paper on Plan Caching listed in the Further Reading section.
There is a plan for the procedure in the cache. That means that everyone can use it, or? No, in this section we will learn that there can be multiple plans for the same procedure in the cache. To understand this, let's consider this contrived example:
CREATE PROCEDURE List_orders_6 AS SELECT * FROM Orders WHERE OrderDate > '12/01/1998' go SET DATEFORMAT dmy go EXEC List_orders_6 go SET DATEFORMAT mdy go EXEC List_orders_6 go
If you run this, you will notice that the first execution returns many orders, whereas the second execution returns no orders. And if you look at the execution plans, you will see that they are different as well. For the first execution, the plan is a Clustered Index Scan (which is the best choice with so many rows returned), whereas the second execution plan uses Index Seek with Key Lookup (which is the best when no rows are returned).
How could this happen? Did SET DATEFORMAT cause recompilation? No, that would not be smart. In this example, the executions come one after each other, but they could just as well be submitted in parallel by different users with different settings for the date format. Keep in mind that the entry for a stored procedure in the plan cache is not tied to a certain session or user, but it is global to all connected users.
Instead the answer is that SQL Server creates a second cache entry for the second execution of the procedure. We can see this if we peek into the plan cache with this query:
SELECT qs.plan_handle, a.attrlist
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) est
CROSS APPLY (SELECT epa.attribute + '=' + convert(nvarchar(127), epa.value) + ' '
FROM sys.dm_exec_plan_attributes(qs.plan_handle) epa
WHERE epa.is_cache_key = 1
ORDER BY epa.attribute
FOR XML PATH('')) AS a(attrlist)
WHERE est.objectid = object_id ('dbo.List_orders_6')
AND est.dbid = db_id('Northwind')
Reminder: You need the server-level permission VIEW SERVER PERFORMANCE STATE to run queries against the plan cache. On versions prior to SQL 2022, you need the permission VIEW SERVER STATE.
The DMV (Dynamic Management View) sys.dm_exec_query_stats has one entry for each query currently in the plan cache. If a procedure has multiple statements, there is one row per statement. Of interest here is sql_handle and plan_handle. I use sql_handle to determine which procedure the cache entry relates to (later we will see examples where we also retrieve the query text) so that we can filter out all other entries in the cache. Most often you use plan_handle to retrieve the query plan itself, and we will see an example of this later, but in this query I access a DMV that returns the attributes of the query plan. More specifically, I return the attributes that are cache keys. When there is more than one entry in the cache for the same procedure, the entries have at least one difference in the cache keys. A cache key is a run-time setting, which for one reason or another calls for a different query plan. Most of these settings are controlled with a SET command, but not all.
The query above returns two rows, indicating that there are two entries for the procedure in the cache. The output may look like this:
plan_handle attrlist
------------------------------- -------------------------------------------------
0x0500070064EFCA5DB8A0A90500... compat_level=150 date_first=7 date_format=1
set_options=4347 user_id=1
0x0500070064EFCA5DB8A0A80500... compat_level=150 date_first=7 date_format=2
set_options=4347 user_id=1
To save space, I have abbreviated the plan handles and deleted many of the values in the attrlist column. I have also folded that column into two lines. If you run the query yourself, you can see the complete list of cache keys, and there are quite a few of them. If you look up the topic for sys.dm_exec_plan_attributes in Books Online, you will see descriptions for many of the plan attributes, but you will also note that far from all cache keys are documented. In this article, I will not dive into all cache keys, not even the documented ones, but focus only on the most important ones.
As I said, the example is contrived, but it gives a good illustration to why the query plans must be different: different date formats may yield different results. A somewhat more normal example is this:
EXEC sp_recompile List_orders_2 go SET DATEFORMAT dmy go EXEC List_orders_2 '12/01/1998' go SET DATEFORMAT mdy go EXEC List_orders_2 '12/01/1998' go
(The initial sp_recompile is to make sure that the plan from the previous example is flushed.) This example yields the same results and the same plans as with List_orders_6 above. That is, the two query plans use the actual parameter value when the respective plan is built. The first query uses 12 Jan 1998, and the second 1 Dec 1998.
A very important cache key is set_options. This is a bit mask that gives the setting of a number of SET options that can be ON or OFF. If you look further in the topic of sys.dm_exec_plan_attributes, you find a listing that details which SET option each bit describes. (You will also see that there are a few more items that are not controlled by the SET command.) Thus, if two connections have any of these options set differently, the connections will use different cache entries for the same procedure – and therefore they could be using different query plans, with possibly big difference in performance.
One way to translate the set_options attribute is to run this query:
SELECT convert(binary(4), 4347)
This tells us that the hex value for 4347 is 0x10FB. Then we can look in Books Online and follow the table to find out that the following SET options are in force: ANSI_PADDING, Parallel Plan, CONCAT_NULL_YIELDS_NULL, ANSI_WARNINGS, ANSI_NULLS, QUOTED_IDENTIFIER, ANSI_NULL_DFLT_ON and ARITHABORT.
You can also use this table-valued function that I have written and run:
SELECT Set_option FROM setoptions (4347) ORDER BY Set_option
Note: You may be wondering what Parallel Plan is doing here, not the least since the plan in the example is not parallel. When SQL Server builds a parallel plan for a query, it may later also build a non-parallel plan if the CPU load in the server is such that it is not defensible to run a parallel plan. It seems that for a plan that is always serial that the bit for parallel plan is nevertheless set in set_options.
To simplify the discussion, we can say that each of these SET options – ANSI_PADDING, ANSI_NULLS etc – is a cache key on its own. The fact that they are added together in a singular numeric value is just a matter of packaging.
About all of the SET ON/OFF options that are cache keys exist because of legacy reasons. Originally, in the dim and distant past, SQL Server included a number of behaviours that violated the ANSI standard for SQL. With SQL Server 6.5, Microsoft introduced all these SET options (save for ARITHABORT, which was in the product already in 4.x), to permit users to use SQL Server in an ANSI-compliant way. In SQL 6.5, you had to use the SET options explicitly to get ANSI compliance, but with SQL 7, Microsoft changed the defaults for clients that used the new versions of the ODBC and OLE DB APIs. The SET options still remained to provide backwards compatibility for older clients.
Note: In case you are curious what effect these SET options have, I refer you to Books Online. Some of them are fairly straight-forward to explain, whereas others are just too confusing. To understand this article, you only need to understand that they exist, and what impact they have on the plan cache.
Alas, Microsoft did not change the defaults with full consistency, and even today the defaults depend on how you connect, as detailed in the table below.
| Applications using ADO .Net, ODBC or OLE DB |
SSMS | SQLCMD, OSQL, BCP, SQL Server Agent |
DB-Library (very old) | |
|---|---|---|---|---|
| ANSI_NULL_DFLT_ON | ON | ON | ON | OFF |
| ANSI_NULLS | ON | ON | ON | OFF |
| ANSI_PADDING | ON | ON | ON | OFF |
| ANSI_WARNINGS | ON | ON | ON | OFF |
| CONCAT_NULL_YIELDS_NULL | ON | ON | ON | OFF |
| QUOTED_IDENTIFIER | ON | ON | OFF | OFF |
| ARITHABORT | OFF | ON | OFF | OFF |
You might see where this is getting at. Your application connects with ARITHABORT OFF, but when you run the query in SSMS, ARITHABORT is ON and thus you will not reuse the cache entry that the application uses, but SQL Server will compile the procedure anew, sniffing your current parameter values, and you may get a different plan than from the application. So there you have a likely answer to the initial question of this article. There are a few more possibilities that we will look into in the next chapter, but by far the most common reason for slow in the application, fast in SSMS is parameter sniffing and the different defaults for ARITHABORT. (If that was all you wanted to know, you can stop reading. If you want to fix your performance problem – hang on! And, no, putting SET ARITHABORT ON in the procedure is not the solution.)
Besides the SET command and the defaults above, ALTER DATABASE permits you to say that a certain SET option always should be ON by default in a database and thus override the default set by the API. These options are intended for very old applications running DB-Library as listed in the right-most column above. While the syntax may indicate so, you cannot specify that an option should be OFF this way. Also, beware that if you test these options from Management Studio, they may not seem to work, since SSMS submits explicit SET commands, overriding any default. There is also a server-level setting for the same purpose, the configuration option user options which is a bit mask. You can set the individual bits in the mask from the Connection pages of the Server Properties in Management Studio. Overall, I recommend against controlling the defaults this way, as in my opinion they mainly serve to increase the confusion.
It is not always the run-time setting of an option that applies. When you create a procedure, view, table etc, the settings for ANSI_NULLS and QUOTED_IDENTIFIER, are saved with the object. That is, if you run this:
SET ANSI_NULLS, QUOTED_IDENTIFIER OFF go CREATE PROCEDURE stupid @x int AS IF @x = NULL PRINT "@x is NULL" go SET ANSI_NULLS, QUOTED_IDENTIFIER ON go EXEC stupid NULL
It will print
@x is NULL
(When QUOTED_IDENTIFIER is OFF, double quote (") is a string delimiter on equal basis with single quote ('). When the
setting is ON, double quotes delimit identifiers in the same way that square
brackets ([]) do and the PRINT statement would yield a compilation
error.)
In addition, the setting for ANSI_PADDING is saved per table column where it is applicable, that is, the data types varchar and varbinary.
All these options and different defaults are certainly confusing, but here
are some pieces of advice. First, remember that the first six of these seven
options exist only to
supply backwards compatibility, so there is little reason why you should ever
have any of them OFF. Yes, there are situations when some of them may seem to buy a little more
convenience if they are OFF, but don't fall for that temptation. One complication here, though,
is that the SQL Server tools spew out SET commands for some of these options
when you script objects. Thankfully, they mainly produce SET ON commands that
are harmless. (But when you script a table, scripts may have a SET ANSI_PADDING OFF at the end. You can control this under Tools->Options->Scripting where you can set Script ANSI_PADDING commands to False, which I recommend.)
Next, when it comes to ARITHABORT, you should know that in SQL 2005 and later versions, this setting has zero impact as long as ANSI_WARNINGS is ON. (To be precise: it has no impact as long as the compatibility level is 90 or higher.) Thus, there is no reason to turn it on for the sake of the matter. And when it comes to SQL Server Management Studio, you might want do yourself a favour, and open this dialog and uncheck SET ARITHABORT as highlighted:
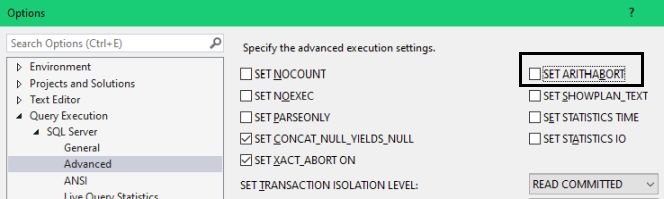
This will change your default setting for ARITHABORT when you connect with SSMS. It will not help you to make your application run faster, but you will at least not have to be perplexed by getting different performance in SQL Server Management Studio.
Note: You may note that on this page I have checked SET XACT_ABORT ON, which is unchecked by default. This setting is not a cache key and has no effect on performance. However, it has an effect on what happens in case of an execution error, which I discuss in my article Error and Transaction in SQL Server. While unrelated to this article, I absolutely recommend you to have this setting checked in SSMS.
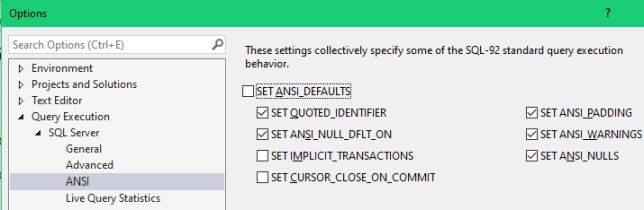
For reference, below is how the ANSI page should look like. A very strong recommendation: never change anything on this page!
When it comes to SQLCMD and OSQL, make the habit to always use the
-I option, which causes these tools to run with QUOTED_IDENTIFIER
ON. The corresponding option for BCP is -q. (To confuse, -q has one more effect for BCP which I discuss in my article Using the Bulk-Load Tools in SQL Server.) It's a little more difficult in Agent, since there is no way to change the default for Agent – at least I have not found any. Then again, if you only run stored procedures from your job steps, this is not an issue, since the saved setting for stored procedures takes precedence. But if you would run loose batches of SQL from Agent jobs, you could face the problem with different query plans in the job and SSMS because of the different defaults for QUOTED_IDENTIFER. For such jobs, you should always include the command SET QUOTED_IDENTIFIER ON as the first command in the job step.
We have already looked at SET DATEFORMAT, and there are two more options in that group: LANGUAGE and DATEFIRST. The default language is configured per user, and there is a server-wide configuration option which controls what is the default language for new users. The default language controls the default for the other two. Since they are cache keys, this means that two users with different default languages will have different cache entries, and may thus have different query plans.
My recommendation is that you should try to avoid being dependent on language and date settings in SQL Server altogether. For instance, in as far as you use date literals at all, use a format that is always interpreted the same, such as YYYYMMDD. (For more details about date formats, see the article The ultimate guide to the datetime datatypes by SQL Server MVP Tibor Karaszi.) If you want to produce localised output from a stored procedure depending on the user's preferred language, it may be better to roll your own than rely on the language setting in SQL Server.
To get a complete picture of how SQL Server builds the query plan, we need to study what happens when individual statements are recompiled. Above, I mentioned a few situations where it can happen, but at that point I did not go into details.
The procedure below is certainly contrived, but it serves well to demonstrate what happens.
CREATE PROCEDURE List_orders_7 @fromdate datetime,
@ix bit AS
SELECT @fromdate = dateadd(YEAR, 2, @fromdate)
SELECT * FROM Orders WHERE OrderDate > @fromdate
IF @ix = 1 CREATE INDEX test ON Orders(ShipVia)
SELECT * FROM Orders WHERE OrderDate > @fromdate
go
EXEC List_orders_7 '19980101', 1
When you run this and look at the actual execution plan, you will see that the plan for the first SELECT is a Clustered Index Scan, which agrees with what we have learnt this far. SQL Server sniffs the value 1998-01-01 and estimates that the query will return 267 rows which is too many to read with Index Seek + Key Lookup. What SQL Server does not know is that the value of @fromdate changes before the queries are executed. Nevertheless, the plan for the second, identical, query is precisely Index Seek + Key Lookup and the estimate is that one row will be returned. This is because the CREATE INDEX statement sets a mark that the schema of the Orders table has changed, which triggers a recompile of the second SELECT statement. When recompiling the statement, SQL Server sniffs the value of the parameter which is current at this point, and thus finds the better plan.
Run the procedure again, but with different parameters (note that the date is two years earlier in time):
EXEC List_orders_7 '19960101', 0
The plans are the same as in the first execution, which is a little more exciting than it may seem at first glance. On this second execution, the first query is recompiled because of the added index, but this time the scan is the "correct" plan, since we retrieve about one third of the orders. However, since the second query is not recompiled now, the second query runs with the Index Seek from the previous execution, although now it is not an efficient plan.
Before you continue, clean up:
DROP INDEX test ON Orders DROP PROCEDURE List_orders_7
As I said, this example is contrived. I made it that way, because I wanted a compact example that is simple to run. In a real-life situation, you may have a procedure that uses the same parameter in two queries against different tables. The DBA creates a new index on one of the tables, which causes the query against that table to be recompiled, whereas the other query is not. The key takeaway here is that the plans for two statements in a procedure may have been compiled for different "sniffed" parameter values.
When we have seen this, it seems logical that this could be extended to local variables as well. But this is not the case:
CREATE PROCEDURE List_orders_8 AS DECLARE @fromdate datetime SELECT @fromdate = '20000101' SELECT * FROM Orders WHERE OrderDate > @fromdate CREATE INDEX test ON Orders(ShipVia) SELECT * FROM Orders WHERE OrderDate > @fromdate DROP INDEX test ON Orders go EXEC List_orders_8
In this example, we get a Clustered Index Scan for both SELECT statements, despite that the second SELECT is recompiled during execution and the value of @fromdate is known at this point.
Note: if you add the hint OPTION (RECOMPILE), it is different. In this case, the values of local variables are considered. We will look more at this hint later in this article.
So far I have talked about scalar parameters and variables. Let's now turn to table variables, where things work differently, and there is also a difference between different versions of SQL Server. Consider this script:
ALTER DATABASE Northwind SET COMPATIBILITY_LEVEL = 140
go
CREATE PROCEDURE List_orders_9 AS
DECLARE @ids TABLE (a int NOT NULL PRIMARY KEY)
INSERT @ids (a)
SELECT OrderID FROM Orders
SELECT COUNT(*)
FROM Orders O
WHERE EXISTS (SELECT *
FROM @ids i
WHERE O.OrderID = i.a)
CREATE INDEX test ON Orders(ShipVia)
SELECT COUNT(*)
FROM Orders O
WHERE EXISTS (SELECT *
FROM @ids i
WHERE O.OrderID = i.a)
DROP INDEX test ON Orders
go
EXEC List_orders_9
go
DROP PROCEDURE List_orders_9
Note that the first statement will fail if you are on SQL 2016 or earlier. In such case, just ignore the error, but you will not be able to run the second part of this lab.
When you run this, you will get in total four execution plans. The two of interest are the second and fourth plans that come from the two identical SELECT COUNT(*) queries. I have included the interesting parts of the plans here:
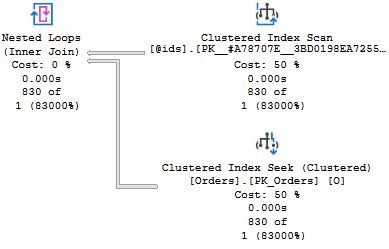
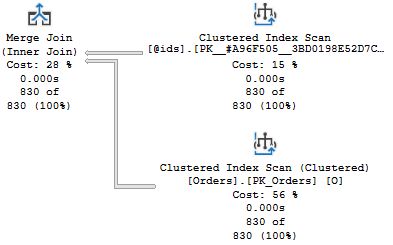
In the first plan, the one to the left, SQL Server estimates that there is one row in the table variable (recall that when it says "830 of 1", this means 830 actual and 1 estimated), and as a consequence of that estimate, the optimizer settles for a Nested Loops Join operator together with a Clustered Index Seek on the Orders table. This is a poor choice in this case, since all rows are returned. But @ids is a local variable, and SQL Server has no knowledge of how many rows there are in the table when the procedure is compiled initially. The creation of an index triggers a recompile of the second SELECT statement before it is executed, and in contrast to a local scalar variable, SQL Server "sniffs" the cardinality of @ids, and you can see in the screen shot to the right that the estimate is now 830, and this leads to a better plan choice with a Merge Join.
If you are on SQL 2019, change 140 to 150 on the first line above and re-run. What you will find is that now the first execution also has a correct estimate for @ids, and the plan is a Merge Join. This is because of enhancement in SQL 2019. It is a common pattern to declare a table variable, populate it with many rows and then use it in a query. This often leads to poor performance, because the plan is optimised for one row in the table variable when there are many. For this reason, Microsoft introduced deferred compilation for statements that refer to table variables. That is, if the compatibility level is 150 or higher, SQL Server does not compile any query plan for the two SELECT statements when the procedure starts, but defers this until execution reaches those statements. The plan that is created at this point is put into cache and reused on further executions.
Both these behaviours, the original behaviour with sniffing the local variable on statement recompile, and the deferred compilation introduced in SQL 2019 are generally beneficiary. However, there is a risk that you can run into issues akin to parameter sniffing. Say that on the first execution there are 2000 rows in the table variable, but on subsequent executions there are only three to five rows. These latter executions will then run with a plan optimised for 2000 rows, which may not be the best for these smaller executions.
Note: It is possible to disable deferred compilation of statements with table variables, either for a specific query with a query hint or on database level with a database-scoped configuration. Observe that these settings do not apply to sniffing the cardinality of a table variable when a statement is recompiled.
Finally, let's look at table-valued parameters. For these you will never get any blind assumption of one row, but SQL Server will sniff the cardinality of the parameter when it performs the initial compilation of the procedure. Here is an example:
CREATE TYPE temptype AS TABLE (a int NOT NULL PRIMARY KEY)
go
CREATE PROCEDURE List_orders_10 @ids temptype READONLY AS
SELECT COUNT(*)
FROM Orders O
WHERE EXISTS (SELECT *
FROM @ids i
WHERE O.OrderID = i.a)
go
DECLARE @ids temptype
INSERT @ids (a)
SELECT OrderID FROM Orders
EXEC List_orders_10 @ids
go
DECLARE @ids temptype
INSERT @ids (a) VALUES(11000)
EXEC List_orders_10 @ids
go
DROP PROCEDURE List_orders_10
DROP TYPE temptype
The query plan for this procedure is the same as for the second SELECT query in List_orders_9, that is Merge Join + Clustered Index Scan of Orders, since SQL Server sees the 830 rows in @ids when the query is compiled. The execution plan is the same for the second execution of List_orders_10, although this time the execution plan is not optimal. We know why this happens: SQL Server reuses the cached execution plan.
In this chapter, we have looked at how SQL Server compiles a stored procedure and what significance the actual parameter values have for compilation. We have seen that SQL Server puts the plan for the procedure into cache, so that the plan can be reused later. We have also seen that there can be more than one entry for the same stored procedure in the cache. We have seen that there is a large number of different cache keys, so potentially there can be very many plans for a single stored procedure. But we have also learnt that many of the SET options that are cache keys are legacy options that you should never change.
In practice, the most important SET option is ARITHABORT, because the default for this option is different in an application and in SQL Server Management Studio. This explains why you can spot a slow query in your application, and then run it at good speed in SSMS. The application uses a plan which was compiled for a different set of sniffed parameter values than the actual values, whereas when you run the query in SSMS, it is likely that there is no plan for ARITHABORT ON in the cache, so SQL Server will build a plan that fits with your current parameter values.
You have also understood that you can verify that this is the case by running this command in your query window:
SET ARITHABORT OFF
and with great likelihood, you will now get the slow behaviour of the application also in SSMS. If this happens, you know that you have a performance problem related to parameter sniffing. What you may not know yet is how to address this performance problem, and in the following chapters I will discuss possible solutions, before I return to the theme of compilation, this time for ad-hoc queries, a.k.a. dynamic SQL. In the last appendix, I will discuss a quite special situation reminiscent of parameter sniffing related to temp-table caching.
Note: There are always these funny variations. An application I worked with for many years actually issued SET ARITHABORT ON when it connected, so we should never have seen this confusing behaviour in SSMS. Except that we did. An older component of the application also issued the command SET NO_BROWSETABLE ON on connection. I have never been able to understand the impact of this undocumented SET command, but I seem to recall that it is related to early versions of "classic" ADO. And, yes, this setting is a cache key.
Before we delve into how to address performance problems related to parameter sniffing, which is quite a broad topic, I would first like to give some coverage to a couple of cases where parameter sniffing is not involved, but where you nevertheless may experience different performance in the application and SSMS.
I have already touched on this, but it is worth expanding on a bit.
Occasionally, I see people in the forums telling me that their stored procedure is slow, but when they run the same query outside of the procedure it's fast. After a few posts in the thread, the truth is revealed: The query they are struggling with refers to variables, be that local variables or parameters. To troubleshoot the query on its own, they have replaced the variables with constants. But as we have seen, the resulting stand-alone query is quite different, and SQL Server can make more accurate estimates with constants instead of variables, and therefore it arrives at a better plan. Furthermore, SQL Server does not have to consider that the constant may have a different value next time the query is executed.
A similar mistake is to make the parameters into variables. Say that you have:
CREATE PROCEDURE some_sp @par1 int AS ... -- Some query that refers to @par1
You want to troubleshoot this query on its own, so you do:
DECLARE @par1 int SELECT @par1 = 4711 -- query goes here
From what you have learnt here, you know that this is very different from when @par1 really is a parameter. SQL Server has no idea about the value for @par1 when you declare it as a local variable and will make standard assumptions.
But if you have a 1000-line stored procedure, and one query is slow, how do you run it stand-alone with great fidelity, so that you have the same presumptions as in the stored procedure?
One way to tackle this is to embed the query in sp_executesql:
EXEC sp_executesql N'-- Some query that refers to @par1', N'@par1 int', 4711
You will need to double any single quotes in the query to be able to put it in a character literal. If the query refers to local variables, you should assign them in the block of dynamic SQL and not pass them as parameters so that you have the same presumptions as in the stored procedure.
Another option is to create a dummy procedure with the problematic statement; this saves from doubling any quotes. To avoid litter in the database, you could create a temporary stored procedure:
CREATE PROCEDURE #test @par1 int AS -- query goes here.
As with dynamic SQL, make sure that local variables are locally declared also in your dummy. I will need to add the caveat I have not investigated whether SQL Server has special tweaks or limitations when optimising temporary stored procedures. Not that I see why there should be any, but I have been burnt before...
You should not forget that one possible reason that the procedure ran slow in the application was simply a matter of blocking. When you tested the query three hours later in SSMS, the blocker had completed its work. If you find that no matter how you run the procedure in SSMS, with or without ARITHABORT, the procedure is always fast, blocking is starting to seem a likely explanation. Next time you are alarmed that the procedure is slow, you should start your investigation with some blocking analysis. That is a topic which is completely outside the scope for this article, but for a good tool to investigate locking, see my beta_lockinfo.
Let's say that you run a query like this in two different databases:
SELECT ... FROM dbo.sometable JOIN dbo.someothertable ON ... JOIN dbo.yetanothertable ON ... WHERE ...
You find that the query performs very differently in the two databases. There can be a whole lot of reasons for these differences. Maybe the data sizes are entirely different in one or more of the tables, or the data is distributed differently. It could be that the statistics are different, even if the data is identical. It could also be that one database has an index that the other database has not.
Say that the query instead goes:
SELECT ... FROM thatdb.dbo.sometable JOIN thatdb.dbo.someothertable ON ... JOIN thatdb.dbo.yetanothertable ON ... WHERE ...
That is, the query refers to the tables in three-part notation. And yet you find that the query runs faster in SSMS than in the application or vice versa. But when you get the idea to change the database in SSMS to be the same as in the application, you get slow performance in SSMS as well. What is going on? It can certainly not be anything of what I discussed above, since the tables are the same, no matter the database you issue the query from.
The answer is that it may be parameter sniffing, because if you look at the output of the query I introduced in the section Different Plans for Different Settings, you will see that dbid is one of the cache keys. That is, if you run the same query against the same tables from two different databases, you get different cache entries, and thus there can be different plans. And, as we have learnt, one of the possible reasons for this is parameter sniffing. But it could also be that the settings for the two databases are different:
Thus, if this occurs to you, run this query:
SELECT * FROM sys.databases WHERE name IN ('slowdb', 'fastdb')
(Obviously, you should replace slowdb and fastdb with the names of the actual databases you ran from.) Compare the rows, and make note of the differences. Far from all the columns you see affect the plan choice. The by far most important one is the compatibility level. When Microsoft makes enhancements to the optimizer in a new version of SQL Server, they only make these enhancements available in the latest compatibility level, because although they are intended to be enhancements, there will always be queries that will be negatively affected by the change and run a lot slower.
If you are on SQL 2016 or later, you also need to look in sys.database_scoped_configurations and compare the settings between the two databases. (This view does not hold the database id or the name, but each database has its own version.) Quite a few of these settings affect the work of the optimizer, which could lead to different plans.
What you would do once you have identified the difference depends on the situation. But generally, I recommend against changing away from the defaults. (Starting with SQL 2017, sys.database_scoped_configurations has a column is_value_default which is 1, if the current setting is the default setting.)
For instance, if you find that the slow plan comes from a database with a lower compatibility level, consider changing the compatibility level for that database. But if the slow plan occurs with the database with the higher compatibility level, you should not change the setting, but rather work with the query and available indexes to see what can be done. In my experience, when a query regresses when going to a newer version of the optimizer, there is usually something that is problematic, and you were only lucky that the query ran fast on the earlier version.
There is one quite obvious exception to the rule of sticking with the defaults: if you find that in the fast database, the database-scoped configuration QUERY_OPTIMIZER_HOTFIXES is set to 1, you should consider to enable this setting for the other database as well, as this will give you access to optimizer fixes released after the original release of the SQL Server version you are using.
Just to make it clear: the database settings do not only apply to queries with tables in three-part notation, but they can also explain why the same query or stored procedure with tables in one- or two-part notation gets different plans and performance in seemingly similar databases.
You have a query in a stored procedure that is slow. But when you put the query in a temporary procedure like I discussed above, it's fast. When you compare the query plans, you find that the fast version uses an indexed view, an index on a computed column, or a filtered index, but the slow procedure does not.
For the optimizer to consider any of these types of indexes, these settings must be ON: QUOTED_IDENTIFIER, ANSI_NULLS, ANSI_WARNINGS, ANSI_PADDING, and CONCAT_NULL_YIELDS_NULL. Furthermore, NUMERIC_ROUNDABORT must be OFF. Of these settings, QUOTED_IDENTIFIER and ANSI_NULLS are saved with the procedure. So in the scenario I described in the previous paragraph, a likely cause is that the stored procedure was created with QUOTED_IDENTIFIER and/or ANSI_NULLS set to OFF. You can investigate the stored settings for your procedure with this query:
SELECT objectpropertyex(object_id('your_sp'), 'IsQuotedIdentOn'),
objectpropertyex(object_id('your_sp'), 'IsAnsiNullsOn')
If you see 0 in any of these columns, make sure that the procedure is reloaded with the proper settings.
There are two reasons related to SQL tools that can cause this to happen. First, as I noticed earlier, SQLCMD by default connects with SET QUOTED_IDENTIFIER OFF, so if you deploy procedures with SQLCMD this can happen. Use the ‑I option to force QUOTED_IDENTIFIER ON! The other reason is something you would mainly encounter in a database that started its life in SQL 2000 or earlier. SQL 2000 came with a tool Enterprise Manager which always emitted SET ANSI_NULLS OFF and SET QUOTED_IDENTIFIER OFF before you created a stored procedure, and this was nothing you could configure. Later, when the database started to be maintained with SSMS, SSMS faithfully scripted these settings, and unless someone manually changed them they were retained through the years.
You can use this query to find all procedures with bad settings in your database:
SELECT o.name
FROM sys.sql_modules m
JOIN sys.objects o ON m.object_id = o.object_id
WHERE (m.uses_quoted_identifier = 0 or
m.uses_ansi_nulls = 0)
AND o.type NOT IN ('R', 'D')
Normally, problems related to indexed views and similar are due to stored settings, but obviously, if the application would meddle with any of the other four SET options, for instance, submit SET ANSI_WARNINGS OFF when connecting, this would also disqualify these types of indexes from being used, and thus be a reason for slow in the application, fast in SSMS.
Finally, if you have a database with compatibility level 80 (which is not supported on SQL 2012 and later), you should know that there is one more setting which must be ON for these indexes to be considered, and that is our favourite, ARITHABORT.
This section concerns an issue with linked servers which mainly occurs when the remote server is earlier than SQL 2012 SP1, but it can appear with later versions as well under some circumstances.
Consider this query:
SELECT C.* FROM SQL_2008.Northwind.dbo.Orders O JOIN Customers C ON O.CustomerID = C.CustomerID WHERE O.OrderID > 20000
I ran this query twice, logged in as two different users. The first user is sysadmin on both servers, whereas the second user is a plain user with only SELECT permissions. To ensure that I would get different cache entries, I used different settings for ARITHABORT.
When I ran the query as sysadmin, I got this plan:

When I ran the query as the plain user, the plan was different:

How come the plans are different? It's certainly not parameter sniffing because there are no parameters. As always when a query plan has an unexpected shape or operator, it is a good idea to look at the estimates, and if you look at the numbers below the Remote Query operators, you can see that the estimates are different. When I ran as sysadmin, the estimate was 1 row, which is a correct number, since there are no orders in Northwind where the order ID exceeds 20000. (Recall that the optimizer never assumes zero rows from statistics.) But when I ran the query as a plain user, the estimate was 249 rows. We recognize this particular number as 30 % of 830 orders, or the estimate for an inequality operation when the optimizer has no information. Previously, this was due to an unknown variable value, but in this case there is no variable that can be unknown. No, it is the statistics themselves that are missing.
As long as a query accesses tables in the local server only, the optimizer can always access the statistics for all tables in the query. This happens internally in SQL Server and there are no extra checks to see whether the user has permission to see the statistics. But this is different with tables on linked servers. When SQL Server accesses a linked server, the optimizer needs to retrieve the statistics on the same connection that is used to retrieve the data, and it needs to use T‑SQL commands which is why permissions come into play. And, unless login mapping has been set up, those are the permissions of the user running the query.
By using Profiler or Extended Events you can see that the optimizer retrieves the statistics in two steps. First it calls the procedure sp_table_statistics2_rowset which returns information about which column statistics there are, as well as the cardinality and density information of the columns. In the second step, it runs DBCC SHOW_STATISTICS to get the full distribution statistics. (We will look closer at this command later in this article.)
Note: to be accurate, the optimizer does not talk to the linked server at all, but it interacts with the OLE DB provider for the remote data source and requests the provider to return the information the optimizer needs.
For sp_table_statistics2_rowset to run successfully the user must have the permission VIEW DEFINITION on the table. This permission is implied if the user has SELECT permission on the table (without which the user would not be able to run the query at all). So, unless the user has been explicitly denied VIEW DEFINITION, this procedure is not so much a concern.
DBCC SHOW_STATISTICS is a different matter. For a long time, running this command required membership in the server role sysadmin or in one of the database roles db_owner or db_ddladmin. This was changed in SQL 2012 SP1, so starting with this version, only SELECT permission is needed.
And this is why I got different results. As you can tell from the server name, my linked server was an instance running SQL 2008. Thus, when I was connected as a user that was sysadmin on the remote instance, I got the full distribution statistics which indicated that there are no rows with order ID > 20000, and the estimate was one row. But when running as the plain user, DBCC SHOW_STATISTICS failed with a permission error. This error was not propagated, but instead the optimizer accepted that there were no statistics and used default assumptions. Since it did get cardinality information from sp_table_statistics2_rowset, it learnt that the remote table has 830 rows, hence the estimate of 249 rows.
From what I said above, this should not be an issue if the linked server runs SQL 2012 SP1 or later, but there can still be obstacles. If the user does not have SELECT permission on all columns in the table, there may be statistics the optimizer is not able to retrieve. Furthermore, according to Books Online, there is a trace flag (9485) which permits the DBA to prevent SELECT permission to be sufficient for running DBCC SHOW_STATISTICS. And more importantly, if row-level security (a feature added in SQL 2016) has been set up for the table, only having SELECT permission is not sufficient as this could permit users to see data they should not have access to. That is, to run DBCC SHOW_STATISTICS on a table with row-level filtering enabled, you need membership in sysadmin, db_owner or db_ddladmin. (Interesting enough, one would expect the same to apply if the table has Dynamic Data Masking enabled, but that does seem to be the case.)
Thus, when you encounter a performance problem where a query that accesses a linked server is slow in the application, but it runs fast when you test it from SSMS (where you presumably are connected as a power user), you should always investigate the permissions on the remote database. (Keep in mind that the access to the linked server may not be overt in the query, but could be hidden in a view.)
If you determine that permissions on the remote database is the problem, what actions could you take? Granting users more permissions on the remote server is of course an easy way out, but absolutely not recommendable from a security perspective. Another alternative is to set up login-mapping so that users log on the remote server with a proxy user with sufficient powers. Again, this is highly questionable from a security perspective.
Rather you would need to tweak the query. For instance, you can rewrite the query with OPENQUERY to force evaluation on the remote server. This can be particularly useful, if the query includes several remote tables, since for the query that runs on the remote server, the remote optimizer has full access to the statistics on that server. (But it can also backfire, because the local optimizer now gets even less statistics information from the remote server.) You can also use the full battery of hints and plan guides to get the plan you want.
I would also recommend that you ask yourself (and the people around you): is that linked-server access needed? Maybe the databases could be on the same server? Could data be replicated? Some other solution? Personally, I try to avoid linked servers as much as possible. In my experience, linked servers often mean hassle.
Before I close this section, I like to repeat: what matters is the permissions on the remote server, not the local server where the query is issued. I also like to point out that I have given a blind eye to what may happen with other remote data sources such as Oracle, MySQL or Access as they have different permission systems of which I'm entirely ignorant. You may or may not see similar issues when running queries against such linked servers.
I got this mail from a reader:
We recently found a SQL Server 2016 select query against CCIs that was slow in the application, and fast in SSMS. Application execution time was 3 to 4 times that of SSMS – looking a bit deeper it was seen that the ratio of CPU time was similar. This held true whether the query was executed in parallel as typical or in serial by forcing MAXDOP 1. An unusual facet was that Query Store was accounting the executions against the same row in sys.query_store_query and sys.query_store_plan, whether from the app or from SSMS.
The application was using a connection string enabling MARS, even though it didn’t need to. Removing that clause from the connection string resulted in SSMS and the application experiencing the same CPU time and elapsed time.
We’ll keep looking to determine the mechanics of the difference. I suspect it may be due to locking behavior difference – perhaps MARS disables lock escalation.
Note: MARS = Multiple Active Result Sets. If you set this property on a connection string, you can run multiple queries on the same connection in an interleaved fashion. It's mainly intended to permit you to submit UPDATE statements as you are iterating through a result set.
The observations from Query Store make it quite clear to me that the execution plan was the same in both cases. Thus, it cannot be a matter of parameter sniffing, different SET options or similar. Interestingly enough, some time later after I had added this section to the article, I got a mail from a second reader who had experienced the same thing. That is, access to a clustered columnstore index was significantly slower with MARS enabled.
This kept me puzzled for a while, and there was too little information to make it possible for me to make an attempt to reproduce the issue. But then I got a third mail on this theme, and Nick Smith was kind to provide a simple example query:
SELECT TOP 10000 SiteId FROM MyTable
That is, it is simply a matter of a query that returns many rows. Note that in this case there was no columnstore index involved, but just a plain-vanilla table. I built a small C# program on this theme and measured execution time with and without MARS. At first, I could not discern any difference at all, but I was running against my local instance. Once I targeted my database in Azure it was a difference of a factor ten. When I connected to a server on the other side of town the difference was a factor of three or four.
It seems quite clear to me that it is a matter of network latency. I assume that the interleaved nature of MARS introduces chattiness on the wire, so the slower and longer the network connection is, the more that chattiness is going to affect you.
Thus, if you find that a query that returns a lot of data runs slow in the application and a lot faster in SSMS, there is all reason to see whether the application specifies MultipleActiveResultSets=true in the connection string. If it does, ask yourself if you need it, and if not take it out.
Could MARS make an application go slower for some other reason? I see no reason to believe so, but it is still a little telling that my first two correspondents mentioned columnstore indexes. Also, the network latency does not really explain the difference in CPU mentioned in the quote above. So, if you encounter a situation where you conclude that MARS slows things down and that there is no network latency, I would be very interested in hearing from you.
This is something Daniel Lopez Atan ran into. He was investigating a procedure that was running slow from the application, but when he tried it in SSMS it was fast. He tried all the tricks in this article, but nothing seemed to fit. But then he noticed that the application ran the procedure inside a transaction. So he tried wrapping the procedure in BEGIN and COMMIT TRANSACTION when he called it from SSMS – and now it was slow from SSMS as well.
This is nothing you will see every time there is a transaction involved, but you may see it with code that runs loops to update data one row at a time (or for one customer at a time or whatever). And it can cut both ways. That is, you may find that you wrap this sort of a procedure in a transaction, it actually runs faster. Confusing, eh? Don't worry, there is a pattern.
Say that you have a loop without any transaction at all where you insert one row at a time. Since every INSERT is its own transaction, SQL Server must wait until the transaction has been hardened, until it can move on. On the other hand, if there is a user-defined transaction around the whole thing, SQL Server can continue directly, fully knowing that if something fails before commit, everything will be rolled back. Thus, the loop now runs quite a bit faster.
However, for reasons I have not fully grasped, if the uncommitted transaction becomes too large, the overhead for a write starts to grow, and eventually it takes considerably longer time to insert a single row, than if there had been no transaction at all, and this is what happened in Daniel's case. I have seen this myself a few times.
So if your performance issue includes loops, you should definitely investigate whether transactions are being used. If they are not, you should consider wrapping the loop in a transaction, possibly with a commit after every thousand rows or so. And vice versa, if it is all one long transaction and it runs faster without, remove the transaction – or even better, keep it, but with commit after every thousand rows. Keep in mind that in either case, you need to understand the business requirements. They may mandate all or nothing, in which case it must remain a single transaction. Or they may mandate that a single bad row must not result in other rows being lost, which rules out the use of transactions at all.
We have learnt how it may come that you have a stored procedure that runs slow in the application, and yet the very same call runs fast when you try it in SQL Server Management Studio: Because of different settings of ARITHABORT you get different cache entries, and since SQL Server employs parameter sniffing, you may get different execution plans.
While the secret behind the mystery now has been unveiled, the main problem still remains: how do you address the performance problem? From what you have read this far, you already know of a quick fix. If you have never seen the problem before and/or the situation is urgent, you can always do:
EXEC sp_recompile problem_sp
As we have seen, this will flush the procedure from the plan cache, and next time it is invoked, there will be a new query plan. And if the problem never comes back, consider the case closed.
But if the problem keeps reoccurring – and unfortunately, this is the more likely outcome – you need to perform a deeper analysis, and in this situation you should make sure that you get hold of the slow plan before you run sp_recompile, or in some other way alter the procedure. You should keep that slow plan around, so that you can examine it, and not the least find what parameter values the bad plan was built for. This is the topic for this chapter.
Note: If you are on SQL 2016 or later and you have enabled Query Store for your database, you can find all information about the plans in the Query Store views, even after the plans have been flushed. In a later chapter, I present Query Store versions of the queries that appear in this chapter.
Before I go on, a small observation: above I recommended that you should change your preferences in SSMS, so that you by default connect with ARITHABORT OFF to avoid this kind of confusion. But there is actually a small disadvantage with having the same settings as the application: you may not observe that the performance problem is related to parameter sniffing. But if you make it a habit when investigating performance issues to run your problem procedure with ARITHABORT both ON and OFF, you can easily conclude whether parameter sniffing is involved.
Also, I would like to clarify one thing. "Parameter-sniffing problems" is a not wholly accurate term, as the problem is not really the parameter sniffing per se. A better term would be parameter-sensitive queries or parameter-sensitive plans, because that's the root cause of the problems. However, "parameter sniffing" is the term used in general parlance for these types of problems, and I have decided to follow this pattern in this article.
All performance troubleshooting requires facts. If you don't have facts, you will be in the situation that Bryan Ferry describes so well in the song Sea Breezes from the first Roxy Music album:
We've been running round in our present state
Hoping help will come from above
But even angels there make the same mistakes
If you don't have facts, not even the angels will be able to help you. The base facts you need to troubleshoot performance issues related to parameter sniffing are:
Almost all of these points apply to about any query-tuning effort. Only the third point is unique to parameter-sniffing issues. That, and the plural in the second point: you want to look at two plans, the good plan and the bad plan. In the following sections, we will look at these points one by one.
First on the list is to find the slow statement – in most cases, the problem lies with a single statement. If the procedure has only one statement, this is trivial. Else, you can use Profiler to find out; the Duration column will tell you. Either just trace the procedure from the application, or run the procedure from Management Studio (with ARITHABORT OFF!) and filter for your own spid.
Yet another option is to use the stored procedure sp_sqltrace, written by Lee Tudor and which I am glad to host on my website. sp_sqltrace takes an SQL batch as parameter, starts a server-side trace, runs the batch, stops the trace and then summarises the result. There are a number of input parameters to control the procedure, for instance how to sort the output. This procedure is particularly useful to determine the slow statement in a loop, since you get the totals aggregated per statement.
In many cases, you can easily find the query plans by running the procedure in Management Studio, after first enabling Include Actual Execution Plan (you find it under the Query menu). This works well, as long as the procedure does not include a multitude of queries, in which case the Execution Plan tab gets too littered to work with. We will look at alternative strategies in the coming sections.
Typically, you would run the procedure like this:
SET ARITHABORT ON go EXEC that_very_sp 4711, 123, 1 go SET ARITHABORT OFF go EXEC that_very_sp 4711, 123, 1
The assumption here is that the application runs with the default options, in which case the first call will give the good plan – because the plan is sniffed for the parameters you provide – and the second call will run with the bad plan which already is in the plan cache. To determine the cache keys in sway, you can use the query in the section Different Plans for Different Settings to see the cache-key values for the plan(s) in the cache. (If you already have tried the procedure in Management Studio, you may have two entries. The column execution_count in sys.dm_exec_query_stats can help you to discern the entries from each other; the one with the low count is probably your attempt from SSMS.)
Once you have the plans, you can easily find the sniffed parameter values. Right-click the left-most operator in the plan – the one that reads SELECT, INSERT, etc – select Properties, which will open a pane to the right. (That is the default position; the pane is detachable.) Here is an example how it can look like:
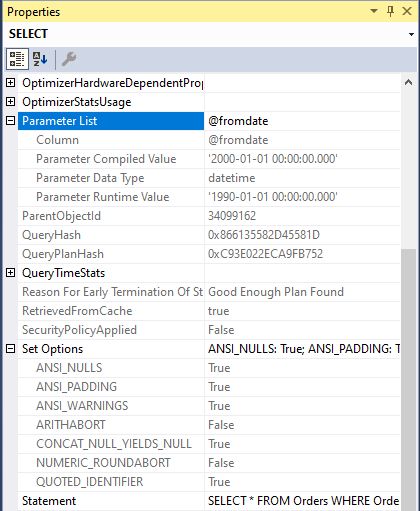
The first Parameter Compiled Value is the sniffed value which is causing you trouble one way or another. If you know your application and its usage pattern, you may get an immediate revelation when you see the value. Maybe you do not, but at least you know now that there is a situation where the application calls the procedure with this possibly odd value. Note also that you can see the settings of some of the SET options that are cache keys.
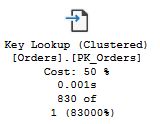
When you look at a query plan, it is far from always apparent what part of the plan that is really costly. But the thickness of the arrows is a good lead. The thicker the arrow, the more rows are passed to the next operator. And if you are looking at an actual execution plan, the thickness is based on the actual number of rows. The graphical plan also offers some useful information for each query operator. As an example, take this Nested Loops operator:

Just below the operator name, you see Cost, which is supposed to convey how much of the cost of the total query that this operator contributes with. My recommendation is that you give this value a miss. The cost is based solely on the estimates, and it has no relation to the actual cost. Least of all if the estimates are inaccurate – and this is not uncommon when you have a performance problem.
Below the cost, you see the execution time. This certainly is a relevant number. You need to keep in mind, though, that the execution time for an operator includes the execution time for the operators to the right sending data into it. Thus, if you see a big difference between an operator and the operators to the right or if, you may be on to something.
Note: Execution times per operator is available from SQL 2014 and up, so if you have SQL 2012 or earlier, you will not see this part.
We looked at the numbers below the execution time in an earlier chapter, but they are important, so it is worth repeating. On top is the actual number of rows, and below that is the estimated number of rows. At the bottom, the actual value is expressed as a percentage of the estimate. When the percentage is high, like 83000 % as in this example, there is a gross misestimate which there is all reason to look into.
It is not always feasible to use SSMS to get the query plans and the sniffed parameter values. The bad query may be running for more minutes than your patience can accept, or the procedure includes so many statements that you get a mess in SSMS. Not the least this can be an issue if the procedure includes a loop that is executed many times.
One option to get hold of the query plan and the sniffed parameters is to retrieve it directly from the plan cache. This is quite convenient with help of the query below, but there is an obvious limitation with this method: you only get the estimates. The actual number of rows and actual number of executions, two values that are very important to understand why a plan is bad, are missing.
This query will return the statements, the sniffed parameter values and the query plans for a stored procedure:
DECLARE @dbname nvarchar(256),
@procname nvarchar(256)
SELECT @dbname = 'Northwind',
@procname = 'dbo.List_orders_11'
; WITH basedata AS (
SELECT qs.statement_start_offset/2 AS stmt_start,
qs.statement_end_offset/2 AS stmt_end,
est.encrypted AS isencrypted, est.text AS sqltext,
epa.value AS set_options, qp.query_plan,
charindex('<ParameterList>', qp.query_plan) + len('<ParameterList>')
AS paramstart,
charindex('</ParameterList>', qp.query_plan) AS paramend
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) est
CROSS APPLY sys.dm_exec_text_query_plan(qs.plan_handle,
qs.statement_start_offset,
qs.statement_end_offset) qp
CROSS APPLY sys.dm_exec_plan_attributes(qs.plan_handle) epa
WHERE est.objectid = object_id (@procname)
AND est.dbid = db_id(@dbname)
AND epa.attribute = 'set_options'
), next_level AS (
SELECT stmt_start, set_options, query_plan,
CASE WHEN isencrypted = 1 THEN '-- ENCRYPTED'
WHEN stmt_start >= 0
THEN substring(sqltext, stmt_start + 1,
CASE stmt_end
WHEN 0 THEN datalength(sqltext)
ELSE stmt_end - stmt_start + 1
END)
END AS Statement,
CASE WHEN paramend > paramstart
THEN CAST (substring(query_plan, paramstart,
paramend - paramstart) AS xml)
END AS params
FROM basedata
)
SELECT set_options AS [SET], n.stmt_start AS Pos, n.Statement,
CR.c.value('@Column', 'nvarchar(128)') AS Parameter,
CR.c.value('@ParameterCompiledValue', 'nvarchar(128)') AS [Sniffed Value],
CAST (query_plan AS xml) AS [Query plan]
FROM next_level n
CROSS APPLY n.params.nodes('ColumnReference') AS CR(c)
ORDER BY n.set_options, n.stmt_start, Parameter
If you have never worked with these DMVs before, I appreciate if this is mainly mumbo-jumbo to you. To keep the focus on the main subject of this article, I will not explain this query right now, but return to it a little later. The only thing I like to give attention to here and now is that you specify the database and the procedure you want to work with in the beginning. You may think this would better be a stored procedure, but it is quite likely that you want to add or remove columns, depending on what you are looking for.
To see the query in action, you can use this test batch (and, yes, the examples get more and more contrived as we move on):
CREATE PROCEDURE List_orders_11 @fromdate datetime,
@custid nchar(5) AS
SELECT @fromdate = dateadd(YEAR, 2, @fromdate)
SELECT *
FROM Orders
WHERE OrderDate > @fromdate
AND CustomerID = @custid
IF @custid = 'ALFKI' CREATE INDEX test ON Orders(ShipVia)
SELECT *
FROM Orders
WHERE CustomerID = @custid
AND OrderDate > @fromdate
IF @custid = 'ALFKI' DROP INDEX test ON Orders
go
SET ARITHABORT ON
EXEC List_orders_11 '19980101', 'ALFKI'
go
SET ARITHABORT OFF
EXEC List_orders_11 '19970101', 'BERGS'
When you have executed this batch, you can run the query above. When I do this I see this result in SSMS (I have split up the screenshot on two images to keep a decent page width):
These are the columns:
SET – The set_options attribute for the plan. As I discussed earlier, this is a bit mask. In this picture, you see the two most likely values. 251 is the default settings and 4347 is the default settings + ARITHABORT ON. If you see other values, you can use the function setoptions to translate the bit mask.
Pos – This is the position for the query in the procedure, counted in characters from the start of the batch that created the procedure, including any comments preceding CREATE PROCEDURE. Not terribly useful in itself, but serves to sort the statements in the order they appear in the procedure.
Statement – The SQL statement. Note that the statements are repeated once for each parameter in the query.
Parameter – The name of the parameter. Only parameters that appear in this statement are listed. As a consequence of this, statements that do not refer to any parameters are not included in the output at all.
Sniffed Value – The compile-time value for the parameter, that is, the value that the optimizer sniffed when it built the plan. Unlike the Properties pane for the plan, you don't see any actual parameter value here. As I discussed previously, the sniffed value for a parameter can be different for different statements in the procedure, and you see an example of this in the picture above.
Query Plan – The query plan. You can double-click the XML document to see the graphical plan directly. As I noted above, this is only the estimated plan. You cannot get any actual values from the cache with this query.
This query refers to some DMVs which not all readers may be acquainted with. It also uses some query techniques that you may not be very familiar with, for instance XQuery. It would take up too much space and distract you from the main topic to dive into the query in full, so I will explain it only briefly. If the query and the explanation go over your head, don't feel too bad about it. As long as you understand the output, you can still have use for the query.
The query uses two CTEs (Common Table Expression). The first CTE, basedata, includes all access to DMVs. We have already seen all of them but sys.dm_exec_text_query_plan. There are two more columns we retrieve from sys.dm_exec_query_stats, to wit statement_start_offset and statement_end_offset. They delimit the statement for this row, and we pass them to sys.dm_exec_text_query_plan to get the plan for this statement only. (Recall that the procedure is a single cache entry with a single plan_handle.) sys.dm_exec_text_query_plan returns the column query_plan which contrary to what you may expect is nvarchar(MAX). The reason for this is that the XML for a query plan may be so deeply nested, that it cannot be represented with SQL Server's built-in xml data type. The CTE returns the query plan as such, but it also extracts the positions for the part in the document where the parameter values appear.
In the next CTE, next_level, I go on and use the values obtained in basedata. The CASE expression extracts the statement from the text returned by sys.dm_exec_sql_text. The way to do this is fairly clunky, not the least with those long column names. Since there is little reason to modify that part of the query, I say no more but refer you to Books Online. Or just believe me when I say it works. :-) The next column in the CTE, params, performs the actual extraction of the parameter values from the query-plan document and converts that element to the xml data type.
In the final SELECT, I shred the params document, so that we get one row per parameter. It can certainly be argued that it is better to have all parameters on a single row, since in this case each statement will only appear once, and here is a variation of the final SELECT that uses more XML functionality to achieve the string aggregation:
SELECT set_options AS [SET], n.stmt_start AS Pos, n.Statement,
(SELECT CR.c.value('@Column', 'nvarchar(128)') + ' = ' +
CR.c.value('@ParameterCompiledValue', 'nvarchar(512)') + ' '
FROM n.params.nodes('ColumnReference') AS CR(c)
FOR XML PATH(''), TYPE).value('.', 'nvarchar(MAX)'),
CAST (query_plan AS xml) AS [Query plan]
FROM next_level n
ORDER BY n.set_options, n.stmt_start
Note: On SQL 2017 or higher, this query could be rewritten using the string_agg function, but that is left as an exercise for the reader.
In the final SELECT, I also convert the query-plan column to XML, but as noted above, this could fail because of limitations with the xml data type. If you get such an error, just comment out that column, or change CAST to TRY_CAST if you are on SQL 2012 or higher. (TRY_CAST returns NULL if the conversion fails.)
Beside the alterations I have already mentioned, there are several ways you could modify the query to retrieve information you find interesting. For instance, you could add more columns from sys.dm_exec_query_stats or more plan attributes. I opted to include the set_options attribute only, since this is the cache key which is most likely to vary. If you would like to include all statements in the procedure, including those that do not refer to any of the input parameters, just change CROSS APPLY on the next-to-last line to OUTER APPLY.
Returning to Management Studio, there is one more option to see query plans and that is a Live Query Plan. The situation when you would use a live query plan is when the query does not complete in reasonable time and you want more information than the estimated plan gives. With a live query plan, the actual values in the plan are updated as the query progresses. You can see both solid lines and dashed lines, where the solid lines represent parts of the plan that have completed. Just like in an actual plan, you see things like 780 of 560, where the first number is the actual number of rows processed by the operator so far and the second number is the estimate. There is also a percentage, from which you can spot gross misestimates.
There are two ways you can see a live query plan in SSMS. One is to run a query from a query window and enable Include Live Query Statistics from the Query menu. This requires that you are connected to SQL 2014 or later. SSMS itself must be version 16 or later; it is not available in SSMS 2014.
If you did not think of enabling live query statistics before starting the query, or you have the query running in the application right now, a second option is to use Activity Monitor (found in Object Explorer, by right-clicking the Server node itself.) Open it and find the pane Active Expensive Queries. You are likely to find your slow query here. You can right-click the query, and the option Show Execution Plan is always there. That gives you the estimated execution plan. If the lightweight execution profiling infrastructure is enabled, the option Show Live Execution Plan is also available. This infrastructure is available if any of these are true:
There is also a DMV in this space that is worth mentioning. sys.dm_exec_query_statistics_xml, introduced in SQL 2016 SP1, permits you to get the execution plan for a currently executing query. It is a function, and it accepts a spid as its only parameter. If the lightweight execution profiling infrastructure is active, you will get the actual values so far. Else you will only get the estimated plan.
Starting with SQL 2019, there is a possibility to get the most recent actual execution plan for a query. To be able to use this feature, you need to enable the database-scoped configuration option LAST_QUERY_PLAN_STATS:
ALTER DATABASE SCOPED CONFIGURATION SET LAST_QUERY_PLAN_STATS = ON
The default for this setting is OFF. When this setting is ON, SQL Server will save a copy of the most recent actual execution plan for a query, which you can retrieve with the DMV sys.dm_exec_query_plan_stats. Here is a demo:
EXEC List_orders_11 '19970101', 'BERGS'
go
DECLARE @dbname nvarchar(256),
@procname nvarchar(256)
SELECT @dbname = 'Northwind',
@procname = 'dbo.List_orders_11'
SELECT qp.query_plan
FROM (SELECT DISTINCT plan_handle, sql_handle FROM sys.dm_exec_query_stats) qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) est
CROSS APPLY sys.dm_exec_query_plan_stats(qs.plan_handle) qp
WHERE est.objectid = object_id (@procname)
AND est.dbid = db_id(@dbname)
If you run this script and click on the returned XML document, you can see that the graphics include execution times and the "actual of estimated" bit. You can also note that you see the plan for the entire stored procedure. The DMV accepts the plan_handle as its only parameter. That is, you cannot supply statement_start/end_offset to extract the plan for a single statement, so for a long procedure, the output can be a bit unwieldy.
I would assume that there is a cost in performance overhead for enabling LAST_QUERY_PLAN_STATS, but I have not investigated how big that overhead may be.
Yet another alternative to get hold of the query plans is to run a trace against the application or against your connection in SSMS. There are several Showplan events you can include in a trace. The most versatile is Showplan XML Statistics Profile which gives you the same information as you see in SSMS when you enable Include Actual Execution Plan.
However, for several reasons a trace is rarely a very good alternative. To start with, enabling query-plan information in a trace adds a lot of overhead to generate that XML information. And observe that this applies even if you narrow your filter to a single spid. The way the trace engine works, all processes still have to generate the event, so this can have a severe impact on a busy server. This is particularly critical if you have a workload that produces many short, quick statements.
Next, if you run the trace in Profiler, you are likely to find it very difficult to set up a good filter that captures what you want to see without getting a lot of noise. One possibility, once the trace has completed, is to save the trace to a table in the database, which permits you to find the interesting information through queries. (But don't ask Profiler to save to a table while the trace is running. The overhead for that is awful.) The plan is in the TextData column. Cast it to xml and then you can view it as I described above.
A slightly better alternative is to use Lee Tudor's sp_sqltrace that I mentioned earlier. It has a parameter to request that query plans should be collected, and you can opt to collect only estimated plans or actual plans. The overall performance on the server is still impacted, but at least you can find the plan you are looking for easily. However, sp_sqltrace will not work for you if you want to look at an application that is using multiple spids.
You can also use Extended Events to get hold of the query plan by capturing the event query_post_execution_showplan, but it is not any better than Trace. Even if you filter your event session for a specific spid, SQL Server activates this event for all processes, so the overall performance is affected in this case as well. (As a matter of fact, I did some quick tests and they indicate that the performance effect is a lot more severe for collecting actual execution plans with Extended Events than with Trace.)
Note: Starting with SQL 2016 SP2 CU3 and SQL 2017 CU11, there is an extended event query_plan_profile which does not have this problem. However, this event only fires if the query has the hint QUERY_PLAN_PROFILE. Which of course your random slow statement in your application will not have. You can inject it with a plan guide, something I discuss later in this text. But it goes without saying that this is a horrendously complicated approach, and I have not tried it myself.
Let's leave the theme of getting query-plan information behind, and instead look at how to find table- and index information.
I assume that you are already acquainted with ways to find out how a table is defined, either with sp_help or through scripting, so I jump directly to the topic of indexes. They too can be scripted or you can use sp_helpindex. But scripting is bulky in my opinion, and sp_helpindex does not support features added in SQL 2005 or later. This query can be helpful:
DECLARE @tbl nvarchar(265)
SELECT @tbl = 'Orders'
SELECT o.name, i.index_id, i.name, i.type_desc,
substring(ikey.cols, 3, len(ikey.cols)) AS key_cols,
substring(inc.cols, 3, len(inc.cols)) AS included_cols,
stats_date(o.object_id, i.index_id) AS stats_date,
i.filter_definition
FROM sys.objects o
JOIN sys.indexes i ON i.object_id = o.object_id
OUTER APPLY (SELECT ', ' + c.name +
CASE ic.is_descending_key
WHEN 1 THEN ' DESC'
ELSE ''
END
FROM sys.index_columns ic
JOIN sys.columns c ON ic.object_id = c.object_id
AND ic.column_id = c.column_id
WHERE ic.object_id = i.object_id
AND ic.index_id = i.index_id
AND ic.is_included_column = 0
ORDER BY ic.key_ordinal
FOR XML PATH('')) AS ikey(cols)
OUTER APPLY (SELECT ', ' + c.name
FROM sys.index_columns ic
JOIN sys.columns c ON ic.object_id = c.object_id
AND ic.column_id = c.column_id
WHERE ic.object_id = i.object_id
AND ic.index_id = i.index_id
AND ic.is_included_column = 1
ORDER BY ic.index_column_id
FOR XML PATH('')) AS inc(cols)
WHERE o.name = @tbl
ORDER BY o.name, i.index_id
As listed, the query will not run on SQL 2005, but just remove the final column, filter_definition, from the result set. This column applies to filtered indexes, a feature added in SQL 2008. As for the column stats_date, see the next section.
To view all statistics for a table, you can use this query:
DECLARE @tbl nvarchar(265)
SELECT @tbl = 'Orders'
SELECT o.name, s.stats_id, s.name, s.auto_created, s.user_created,
substring(scols.cols, 3, len(scols.cols)) AS stat_cols,
stats_date(o.object_id, s.stats_id) AS stats_date,
s.filter_definition
FROM sys.objects o
JOIN sys.stats s ON s.object_id = o.object_id
CROSS APPLY (SELECT ', ' + c.name
FROM sys.stats_columns sc
JOIN sys.columns c ON sc.object_id = c.object_id
AND sc.column_id = c.column_id
WHERE sc.object_id = s.object_id
AND sc.stats_id = s.stats_id
ORDER BY sc.stats_column_id
FOR XML PATH('')) AS scols(cols)
WHERE o.name = @tbl
ORDER BY o.name, s.stats_id
As with the query for indexes, the query does not run for SQL 2005 as listed, but just remove filter_definition from the result set. auto_created refers to statistics that SQL Server creates automatically when it gets the occasion, while user_created refers to indexes created explicitly with CREATE STATISTICS. If both are 0, the statistics exist because of an index.
The column stats_date returns when the statistics most recently were updated. If the date is way back in the past, the statistics may be out of date. The root cause of parameter-sniffing-related problems is usually something else than outdated statistics, but it is always a good idea to look out for this. One thing to keep in mind is that statistics for columns with monotonically increasing data – e.g. id and date columns – quickly go out of date, because queries are often for the most recently inserted data, which is always beyond the last slot in the histogram (more about histograms later).
If you believe statistics are out of date for a table, you can use this command:
UPDATE STATISTICS tbl
This will give you sampled statistics. Often this gives you statistics that are good enough, but sometimes the sampling does not work out well. In this case, it can be worth forcing a full scan of the data. This may be best done with this command:
UPDATE STATISTICS tbl WITH FULLSCAN, INDEX
By adding INDEX to the command, the FULLSCAN update is only performed for statistics for indexes. This can reduce the execution time for UPDATE STATISTICS considerably, since for non-index statistics, UPDATE STATISTICS scans the entire table for each statistics. (Whereas for the indexes, it scans the leaf level of the index which is typically a lot smaller.)
You can also update the statistics for a single index. The syntax for this is not what you may expect:
UPDATE STATISTICS tbl indexname WITH FULLSCAN
Note: there is no period between the table name and the index name, just space.
Note that after updating statistics, you may see an immediate performance improvement in the application. This does not necessarily prove that outdated statistics was the problem. Since the updated statistics cause recompilation, the parameters may be re-sniffed and you get a better plan for this reason.
To see the distribution statistics for an index, use DBCC SHOW_STATISTICS. This command takes two parameters. The first is the table name, whereas the second can be the name of an index or statistics. For instance:
DBCC SHOW_STATISTICS (Orders, OrderDate)
This displays three result sets. I will not cover all of them here, but only say that the last result set is the actual histogram for the statistics. The histogram reflects the distribution that SQL Server has recorded about the data in the table. Here is how the first few lines look in the example:

This tells us that according to the statistics there is exactly one row with OrderDate = 1996-07-04. Then there is one row in the range from 1996-07-05 to 1996-07-07 and two rows with OrderDate = 1996-07-08. (Because RANGE_ROWS is 1 and EQ_ROWS is 2.) The histogram then continues, and there are in total 188 steps for this particular statistics. There are never more than 200 steps in a histogram. For full details on the output, please see the topic for DBCC SHOW_STATISTICS in Books Online. One of the white papers listed in the section Further Reading has more valuable information about statistics and the histogram.
Note: In SQL 2005 there is a bug, so if there is a step for NULL values, DBCC SHOW_STATISTICS fails to show this row. This is a display error, and the value is still there in the histogram.
You do not typically run DBCC SHOW_STATISTICS for all statistics to have the information just in case, but only when you think that the information may be useful to you. We will look at such an example in the next chapter.
For auto-created statistics the name is something like _WA_Sys_00000003_42E1EEFE. This is somewhat cumbersome to use, so in this case DBCC SHOW_STATISTICS permits you to specify the column name instead. Note that you cannot use the column name if there are user-created statistics on the column (through CREATE INDEX or CREATE STATISTICS). The above example appears to contradict that, since there is an index on the OrderDate column. But that index is also called OrderDate!
DBCC SHOW_STATISTICS is probably the easiest to use for manual inspection, but if you want to filter the output or do some processing of it, there is also a DMV, sys.dm_db_stats_histogram, which was introduced in SQL 2016 SP1 CU2. Here is a sample query:
SELECT sh.*
FROM sys.stats s
CROSS APPLY sys.dm_db_stats_histogram(s.object_id, s.stats_id) sh
WHERE s.object_id = object_id('dbo.Orders')
AND s.Name = 'OrderDate'
ORDER BY sh.range_high_key
For this DMV, you don't have the choice of passing names, but you must pass ids. There is also an accompanying DMV, sys.dm_db_stats_properties, that returns the information from the first result set of DBCC SHOW_STATISTICS.
It is important to understand that parameter sniffing in itself is not a problem; au contraire, it is a feature, since without it SQL Server would have to rely on blind assumptions, which in most cases would lead to less optimal query plans. But sometimes parameter sniffing works against you. We can identify three typical situations:
It can be difficult to say beforehand which applies to your situation, and that is why you need to make a careful analysis. In the previous section I discussed what information you need, although I did not always make it clear what for. In addition, there is one more thing I did not list but which is immensely helpful: intimate knowledge about how the application works and its usage pattern.
Since there are several possible reasons why parameter sniffing could give you a headache, this means that there is no single solution that you can apply. Rather there is a host of them, depending on where the root cause lies. In the following I will give some examples of parameter-sniffing related issues and how to address them. Some are real-life examples, others are more generic in nature. Some of the examples focus more on the analysis, others take a straight look at the solution.
Before I go into the real solutions, let me first point out that adding SET ARITHABORT ON to your procedure is not a solution. It will seem to work when you try it. But that is only because you recreated the procedure which forced a new compilation and then the next invocation sniffed the current set of parameters. SET ARITHABORT ON is only a placebo, and not even a good one. The problem will most likely come back. It will not even help you to avoid the confusion with different performance in the application and SSMS, because the overall cache entry will still have ARITHABORT OFF as its plan attribute.
So, don't put SET ARITHABORT ON in your stored procedures. Overall, I strongly discourage you from using any of the SET commands that are cache keys in your code.
Consider this procedure:
CREATE PROCEDURE List_orders_12 @custid nchar(5),
@fromdate datetime,
@todate datetime AS
SELECT *
FROM Orders
WHERE CustomerID = @custid
AND OrderDate BETWEEN @fromdate AND @todate
There is a non-clustered index on CustomerID and another one on OrderDate. Assume that the order activity among customers varies vividly. Many customers make just a handful of orders per year. But some customers are more active, and some real big guys may place several orders per day.
In the Northwind database, the most active customer is SAVEA with 31 orders, whereas CENTC has only one order. Run the below:
EXEC List_orders_12 'SAVEA', '19970811', '19970811' go sp_recompile List_orders_12 go EXEC List_orders_12 'CENTC', '19960101', '19961231'
That is, for SAVEA we only look at the orders for a single day, but for CENTC we look at the orders for an entire year. As you may sense, these two invocations are best served by different indexes. Here is the plan for the first invocation:
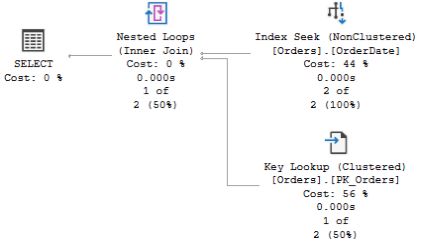
SQL Server here uses the index for OrderDate which is the most selective. The plan for the second invocation is different:
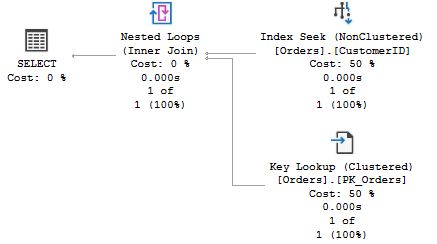
Here CustomerID is the most selective column, and SQL Server uses the index on CustomerID.
One solution to address this is to force recompilation every time with the RECOMPILE query hint:
CREATE PROCEDURE List_orders_12 @custid nchar(5),
@fromdate datetime,
@todate datetime AS
SELECT *
FROM Orders
WHERE CustomerID = @custid
AND OrderDate BETWEEN @fromdate AND @todate
OPTION (RECOMPILE)
With this hint, SQL Server will compile the query every time and since it knows that the plan is not going to be reused, it handles the values of the parameters and local variables as constants. Which, strictly speaking, is different from parameter sniffing. With parameter sniffing, SQL Server uses the parameter value on the first compile as guidance, but it will create the plan so that the result will be correct no matter the actual values of the parameter. This is required for two reasons:
But with OPTION (RECOMPILE) there is no need for such defensive strategies, because it is a compilation with the values here and now. This can often allow for a more efficient execution plan.
In many cases, forcing recompilation every time is quite alright, but there are a few situations where it is not:
More to the point, while forcing recompilation is a solution that is almost always feasible, it is not always the best solution. As a matter of fact, the example we have looked at in this section is probably not very typical for the situation Slow in the application, fast in SSMS. Because, if you have a varying usage pattern, you will be alerted of varying performance within the application itself. So there is all reason to read on, and see if the situation you are facing fits with the other examples I present.
Note: In Appendix B: The Effects of Temp-table Caching, we will look at a situation akin to parameter sniffing which you can experience even if you are using OPTION (RECOMPILE).
It is very common to have forms where users can select from a number of search conditions. For instance, they can select to see orders on a certain date, by a certain customer, for a certain product etc, including combinations of the parameters. Such procedures are sometimes implemented with a WHERE clauses that goes:
WHERE (CustomerID = @custid OR @custid IS NULL) AND (OrderDate = @orderdate OR @orderdate IS NULL) ...
As you may imagine, parameter sniffing is not beneficial for such procedures. I am not going to take up much space on this problem here, for two reasons: 1) As I've already said, problems with such procedures usually manifest themselves with varying performance within the application. 2) I have a separate article devoted to this topic, entitled Dynamic Search Conditions. Short story: OPTION (RECOMPILE) often works very well here.
Some time ago, one of my clients contacted me because one of their customers experienced a severe performance problem with a function in their system. My client said that the same code ran well at other sites, and there had been no change recently to the application. (But you know, clients always say that, it seems.) They had been able to isolate the problematic procedure, which included a query which looked something like this:
SELECT DISTINCT c.* FROM Table_C c JOIN Table_B b ON c.Col1 = b.Col2 JOIN Table_A a ON a.Col4 = b.Col1 WHERE a.Col1 = @p1 AND a.Col2 = @p2 AND a.Col3 = @p3
When executed from the application, the query took 10-15 minutes. When they ran the procedure from SSMS, they found that response time was instant. That was then they called me.
An account was set up for me to make it possible to log in to the site in question. I found that all three tables were of some size, at least a million rows in each. I looked at the indexes for Table_A, and I found that it had some 7-8 indexes. Of interest for this query was:
Thus, there was no index that covered all conditions in the WHERE clause.
When I ran the procedure in SSMS with default settings, the optimizer chose the first index to get data from Table_A. When I changed the setting of ARITHABORT to OFF to match the application, I saw a plan that used the index on Col3.
At this point I ran
DBCC SHOW_STATISTICS (Table_A, Col3_ix)
The output looked like something like this:
| RANGE_HI_KEY | RANGE_ROWS | EQ_ROWS | DISTINCT_RANGE_ROWS | AVG_RANGE_ROWS |
|---|---|---|---|---|
| APRICOT | 0 | 17 | 0 | 1 |
| BANANA | 0 | 123462 | 0 | 1 |
| BLUEBERRY | 0 | 46 | 0 | 1 |
| CHERRY | 0 | 92541 | 0 | 1 |
| FIG | 0 | 1351 | 0 | 1 |
| KIWI | 0 | 421121 | 0 | 1 |
| LEMON | 0 | 6543 | 0 | 1 |
| LIME | 0 | 122131 | 0 | 1 |
| MANGO | 0 | 95824 | 0 | 1 |
| ORANGE | 0 | 10410 | 0 | 1 |
| PEAR | 0 | 46512 | 0 | 1 |
| PINEAPPLE | 0 | 21102 | 0 | 1 |
| PLUM | 0 | 13 | 0 | 1 |
| RASPBERRY | 0 | 95 | 0 | 1 |
| RHUBARB | 0 | 7416 | 0 | 1 |
| STRAWBERRY | 0 | 24611 | 0 | 1 |
That is, there were only 17 distinct values for this column and with a very uneven distribution among these values. I also confirmed this fact by running the query:
SELECT Col3, COUNT(*) FROM Table_A GROUP BY Col3 ORDER BY Col3
I proceeded to look at the bad query plan to see what value that the optimizer had sniffed for @p3. I found that it was – APPLE, a value not present in the table at all! That is, the first time the procedure was executed, SQL Server had estimated that the query would return a single row (recall that it never estimates zero rows), and that the index on Col3 would be the most efficient index to find that single row.
Now, you may ask how it could be that unfortunate that the procedure was first executed for APPLE? Was that just bad luck? Since I don't know this system, I can't tell for sure, but apparently this had happened more than once. I got the impression that this procedure was executed many times as part of some bigger operation. Say that the operation would always start with APPLE. Remember that reindexing a table triggers recompilation, and it is very common to run maintenance jobs at night to keep fragmentation in check. That is, the first call in the morning can be very decisive for your performance. (Why would the operation start with a value that is not in the database? Who knows, but maybe APPLE is an unusual condition that needs to be handled first if it exists. Or maybe it is just the alphabet.)
For this particular query, there are a whole slew of possible measures to address the performance issue.
We have already looked at forcing recompilation, and while it most probably would have solved the problem, it is not likely that it would have been the best solution. Below, I will look into the other options in more detail.
My primary recommendation to the customer was the second on the list: add an index that matches the query perfectly. That is, an index where all columns in the WHERE clauses are index keys, with the least selective column Col3 last among the keys. On top of that, add Col4 as an included column, so that the query can be resolved from the new index alone, without any need to access the data pages.
However, adding a new index is not always a good solution. If you have a table which is accessed in a multitude of ways, it may not be feasible to add indexes that match all WHERE and JOIN conditions, even less to add covering indexes for each and every query. Particularly, this applies to tables with a heavy update rate, like an Orders table. The more indexes you add to a table, the higher the cost to insert, update and delete rows in the table.
How useful is the index on Col3 really? Since I don't know this system, it is difficult to tell. But generally, indexes on columns with only a small set of values are not very selective and thus not that useful. So an option could be to drop the index on Col3 altogether and thereby save the optimizer from this trap. Maybe the index was added at some point in time by mistake, or it was added without understanding of how the database would evolve by time. (Having worked a little more with this client, it seems that they add indexes on all FK columns as a matter of routine. Which may or may not be a good idea.)
It cannot be denied that you have to be a very brave person to drop an index entirely. You can consult sys.dm_db_index_usage_stats to see how much the index is used. Just keep in mind that this DMV is cleared when SQL Server is restarted or the database is taken offline.
Since the distribution in Col3 is so uneven, it is not unlikely that there are queries that look for these rare values specifically. Maybe FIG is "New unprocessed rows". Maybe RASPBERRY means "errors". In this case, it could be beneficial to make Col3_ix a filtered index, a feature added in SQL 2008. For instance, the index definition could read:
CREATE INDEX col3_ix ON Table_A(col3)
WHERE col3 IN ('FIG', 'RASPBERRY', 'APPLE', 'APRICOT')
This has two benefits:
If you know that the index on Col1, Col2 will always be the best index, but you don't want to add or drop any index, you can force the index with:
SELECT c.* FROM Table_C c JOIN Table_B b ON c.Col1 = b.Ccol2 JOIN Table_A a WITH (INDEX = Combo_ix) ON a.Col4 = b.Col1 WHERE a.Col1 = @p1 AND a.Col2 = @p2 AND a.Col3 = @p3
Note: In an older version of this article I suggested that you can say WITH (INDEX (combo_ix, col2_ix)) to give the optimizer the choice between two indexes. However, that was incorrect. You can force multiple indexes, but in that case the optimizer will be compelled to use both indexes. Which can be useful at times, but count that as "advanced".
Index hints are very popular, too popular one might say. You should think twice before you add an index hint, because tomorrow your data distribution may be different, and another index would serve the query better. A second problem is that if you later decide to rearrange the indexes, the query will fail with an error because of the missing index.
OPTIMIZE FOR is a query hint that permits you to control parameter sniffing. For the example query, it could look like this:
SELECT c.* FROM Table_C c JOIN Table_B b ON c.col1 = b.col2 JOIN Table_A a ON a.col4 = b.col1 WHERE a.col1 = @p1 AND a.col2 = @p2 AND a.col3 = @p3 OPTION (OPTIMIZE FOR (@p3 = 'KIWI'))
The hint tells SQL Server to ignore the input value, but instead compile the query as if the input value of @p3 is KIWI, the most common value in Col3. This will surely dissuade SQL Server from using the index.
A second option, available in SQL 2008 and later, is:
OPTION (OPTIMIZE FOR (@p3 UNKNOWN))
Rather than hard-coding any particular value, we can tell SQL Server to make a blind assumption to completely kill parameter sniffing for @p3.
It is worth adding that you can use OPTIMIZE FOR also with locally declared variables, and not only with parameters. Alas, you cannot use OPTIMIZE FOR with table variables or table-valued parameters.
Rather than using @p3 directly in the query, you can copy it to a local variable, and then use the variable in the query. This has the same effect as OPTIMIZE FOR UNKNOWN. And it works on any version of SQL Server.
Yet another option is to change the processing in the application so that it starts with one of the more common values. It's not really a solution I recommend, because it creates an extra dependency between the application and the database. There is a risk that the application two years later is rewritten to accommodate new requirements that PEACH rows must be handled, and this handling is added first...
Then again, there may be a general flaw in the process. Is the application asking for values for one fruit at a time, when it should be getting values for all fruits at once? I helped this client with another query. We had a query-tuning session in a conference room, and I was never able to get really good performance from the query we were working with. But towards the end of the day, the responsible developer said that he knew how to continue, and his solution was to rearchitect the entire process the problematic query was part of.
As you have seen in this example, there are a lot of options to choose from – too many, you may think. But performance tuning often requires you to have a well-stuffed bag of tricks, because different problems call for different solutions.
In a system I worked with for many years, there is a kind of application cache that keeps data in a main-memory database, let's call it MemDb. It is used for several purposes, but the main purpose is to serve as a cache from which the customer's web server can retrieve data rather than querying the database. Typically, in the morning there is a total refresh of the data. When data in a database table is updated, there is a signalling mechanism which triggers MemDb to run a stored procedure to get the delta. In order to find what has changed, MemDb relies on timestamp columns. (A timestamp column holds an 8-byte value that is unique to the database and which grows monotonically. It is automatically updated when the row is inserted or updated. This data type is also known as rowversion.) A typical stored procedure to retrieve changes looks like this:
CREATE PROCEDURE memdb_get_updated_customers @tstamp timestamp AS SELECT CustomerID, CustomerName, Address, ..., tstamp FROM Customers WHERE tstamp > @tstamp
When MemDb calls these procedures, it passes the highest value in the tstamp column for the table in question from the previous call. When the procedure is invoked for a refresh, the main-memory database passes 0x as the parameter to get all rows.
Side note: The actual scheme is more complicated than the above; I have simplified it to focus on what is important for this article. If you are considering something similar, be warned that as shown, this example has lots of issues with concurrent updates, not the least if you use any form of snapshot isolation. SQL 2008 introduced Change Tracking which is a more solid solution, particularly designed for this purpose. I also like to add that MemDb was not my idea, nor was I involved in the design of it.
At one occasion when I monitored the performance for a customer that had just gone live with our system, I noticed that the MemDb procedures had quite long execution times. Since they run very often to read deltas, they have to be very quick. After all, one idea with MemDb is to take load off from the database – not add to it.
For a query like the above to be fast there has to be an index on tstamp, but will this index be used? From what I said above, the first thing in the morning, MemDb would run:
EXEC memdb_get_updated_customers 0x
Then a little later, it would run something like:
EXEC memdb_get_updated_customers 0x000000000003E806
It is not uncommon that during the night that query plans fall out of the cache because of nightly batches that consume a lot of memory. Or there is a maintenance job to rebuild indexes which triggers recompiles. So typically, when the morning refresh runs, there is not any plan in the cache, and the value sniffed is 0x. Given this value, will the optimizer use the index on tstamp? Yes, if it is the clustered index. But since a timestamp column is updated every time a row is updated, it is not a very good choice for the clustered index, and all our indexes on timestamp columns are non-clustered. (And for tables with a high update frequency, also a non-clustered index on a timestamp column may be questionable.) Thus, since the optimizer sees that the parameter indicates that all rows in the table will be retrieved, it settles for a table scan. This plan is put into cache, and subsequent calls also scan the table, even if they are only looking for the most recent rows. And it was this poor performance that I saw.
When you have a situation like this, there are, just like in the previous example, several ways to skin the cat. But before we look at the possibilities, we need to make one important observation: there is no query plan that is good for both cases. We want to use the index to read the deltas, but when making the refresh we want the scan. Thus, only solutions that can yield different plans for the two cases need to apply.
While this solution meets the requirement, it is not a good solution. This means that every time we retrieve a delta, there is compilation. And while the above procedure is simple, some of the MemDb procedures are decently complex with a non-trivial cost for compilation.
Rather than requesting recompilation inside the procedure, it is better to do it in the special case: the refresh. The refresh only happens once a day normally. And furthermore, the refresh is fairly costly in itself, so the cost of recompilation is marginal in this case. That is, when MemDb wants to make a refresh, it should call the procedure in this way:
EXECUTE memdb_get_updated_customers WITH RECOMPILE
As I noted previously, it is likely that there is no plan in the cache early in the morning, so you may ask what's the point? The point is that when you use WITH RECOMPILE with EXECUTE, the plan is not put into cache. Thus, the refresh can run with the scan, but the plan in the cache will be built from the first delta retrieval. (And if the plan for reading the delta still is in the cache, that plan will remain in the cache.)
For the particular problem in this system, this was the solution I mandated. An extra advantage for us was that there was a single code path in MemDb that had to be changed.
There is however a slight problem with this solution. Normally, when you call a stored procedure from a client, you use a special command type where you specify only the name of the procedure. (For instance, CommandType.StoredProcedure in ADO .NET.) The client API then makes an RPC (remote procedure call) to SQL Server, and there is never an EXECUTE statement as such. Very few client APIs seem to expose any method to specify WITH RECOMPILE when you call a procedure through RPC. The workaround is to send the full EXECUTE command, using CommandType.Text or similar, for instance:
cmd.CommandType = CommandType.Text; cmd.Text = "EXECUTE memdb_get_updated_customers @tstamp WITH RECOMPILE";
Note: You should pass the parameters through the Parameters collection or corresponding mechanism in your API; don't inline the values in the string with the EXEC command, as this could open the door for SQL injection.
If you have a situation where you realise that EXECUTE WITH RECOMPILE is the best solution, but it is not feasible to change the client, you can introduce a wrapper procedure. In this example the original procedure would be renamed to memdb_get_updated_customers_inner, and then you would write a wrapper that goes:
CREATE PROCEDURE memdb_get_updated_customers @tstamp timestamp AS
IF @tstamp = 0x
EXECUTE memdb_get_updated_customers_inner @tstamp WITH RECOMPILE
ELSE
EXECUTE memdb_get_updated_customers_inner @tstamp
In many cases this can be a plain and simple solution, particularly if you have a small number of such procedures. (In this system there are many.)
Another approach would be to have different code paths for the two cases:
CREATE PROCEDURE memdb_get_updated_customers @tstamp timestamp AS
IF @tstamp = 0x
BEGIN
SELECT CustomerID, CustomerName, Address, ..., tstamp
FROM Customers
END
ELSE
BEGIN
SELECT CustomerID, CustomerName, Address, ..., tstamp
FROM Customers WITH (INDEX = timestamp_ix)
WHERE tstamp > @tstamp
END
Note that it is important to force the index in the ELSE branch, or else this branch will scan the table if the first call to the procedure is for @tstamp = 0x because of parameter sniffing. If your procedure is more complex and includes joins to other tables, it is not likely that this strategy will work out, even if you force the index on tstamp. The estimates for the joins would be grossly incorrect and the query plans would still be optimized to get all data, and not the delta.
In the situation we had, there was one procedure that was particularly difficult. It retrieved account transactions (this is a system for stock trading). The refresh would not retrieve all transactions in the database, but only from the N most recent days, where N was a system parameter read from the database. In this database, N was 20. The procedure did not read from a single table, but there were umpteen other tables in the query. Rather than having a timestamp parameter, the parameter was an id. This works since transactions are never updated, so MemDb only needs to look for new transactions.
I found that in this case EXECUTE WITH RECOMPILE alone would not save the show, because there were several other problems in the procedure. I found no choice but to have two procedures, one for the refresh and one for the delta. I replaced the original procedure with a wrapper:
CREATE PROCEDURE memdb_get_transactions @transid int AS
IF coalesce(@transid, 0) = 0
EXECUTE memdb_get_transactions_refresh
ELSE
BEGIN
DECLARE @maxtransid int
SELECT @maxtransid = MAX(transid) FROM transactions
EXECUTE memdb_get_transactions_delta @transid, @maxtransid
END
I had to add @maxtransid as a parameter to the delta procedure, because with an open condition like WHERE
transid > @transid, SQL Server would tend to
miss-estimate the number of rows it had to read. Making the interval
closed addressed that issue, and by passing @maxtransid as a parameter, SQL
Server could sniff the value.
From a maintainability perspective, this is by no means a pleasant step to take, not the least when the logic is as complicated as in this case. If you have to do this, it is important that you litter the code with comments to tell people that if they change one procedure, they need to change the other one as well.
Note: a few years later, a colleague rewrote memdb_get_transactions_refresh to become a second wrapper. As I mentioned, it reads some system parameters to determine which transactions to read. To get the refresh to perform decently, he found that he had to pass the values of these system parameters, as well as the interval of transactions ids to read as parameters to an inner procedure to get full benefit of parameter sniffing. (We were still on SQL 2000 at the time. In SQL 2005 or later OPTION (RECOMPILE) would have achieved the same thing.)
There may also be situations where the root cause to the problem is simply poorly written SQL. As just one example, consider this query:
SELECT ... FROM Orders WHERE (CustomerID = @custid OR @custid IS NULL) AND (EmployeeID = @empid OR @empid IS NULL) AND convert(varchar, OrderDate, 101) = convert(varchar, @orderdate, 101)
The idea is that users here are able to search orders for a given date, and optionally they can also specify other search parameters. The programmer here considers that OrderDate may include a time portion, and factors it out by using a format code to convert() that produces a string without time, and to be really sure he performs the same operation on the input parameter. (In Northwind, OrderDate is always without a time portion, but for the sake of the example, I'm assuming that this is not the case.)
For this query, the index on OrderDate would be the obvious choice, but the way the query is written, SQL Server cannot seek that index, because OrderDate is entangled in an expression. This is sometimes referred to as the expression not being sargable, where sarg is short for search argument, that is, something that can be used as a seek predicate in a query. (Personally, I dislike the term "sargable", but since you may see people drop it from time to time, I figured that I should mention this piece of jargon.)
Because the index on OrderDate has been disqualified, the optimizer may settle for any of the other indexes, depending on the input for the first parameter, causing poor performance for other types of searches. The remedy is to rewrite the query, for instance like:
SELECT ... FROM Orders WHERE (CustomerID = @custid OR @custid IS NULL) AND (EmployeeID = @empid OR @empid IS NULL) AND OrderDate >= @orderdate AND OrderDate < dateadd(DAY, 1, @orderdate)
(It seems reasonable to assume that an input parameter which is supposed to be a date does not have any time portion, so there is little reason to litter the code with any extra conversion.)
Poorly written SQL often manifests itself in general performance problems – that is, the query always runs slow – and maybe not so often in situations where parameter sniffing matters. Nevertheless, when you battle your parameter-sniffing problem, there is all reason to investigate whether the query could be written in a way that avoids the dependency of the input parameter for a good plan. There are many ways to write bad SQL, and this is not the place to list them all. Hiding columns in an expression is just one example, albeit a common one. Sometimes the expression is hidden because it is due to implicit conversion, for instance when a string column which is supposed to contain numbers is compared to an integer value. Examine the plan, and when an index is not used as you would expect, go back and look at the query again.
Hitherto we have only looked at stored procedures, and with stored procedures the reason for different performance in the application and in SSMS is most often due to different settings for SET ARITHABORT. If you have an application that does not use stored procedures, but generates the queries in the client or in the middle layer, there are a few more reasons why you may get a new cache entry when you run the query in SSMS and maybe also a different plan than in the application. In this chapter, we will look at these possibilities. We will also look at some solutions for addressing parameter-sniffing problems that mainly are applicable to dynamic SQL.
Dynamic SQL is any SQL which is not part of a stored procedure (or any other type of module). This includes:
Dynamic SQL comes in two flavours, unparameterised and parameterised. In unparameterised SQL, the programmer composes the SQL string by concatenating the language elements with the parameter values. For instance, in T‑SQL:
SELECT @sql = 'SELECT mycol FROM tbl WHERE keycol = ' + convert(varchar, @value) EXEC(@sql)
Or in C#:
cmd.CommandText = "SELECT mycol FROM tbl WHERE keycol = " + value.ToString();
Unparameterised SQL is very bad for several reasons, please see my article The Curse and Blessings of Dynamic SQL for a discussion on good and bad practice with dynamic SQL.
In parameterised SQL, you pass parameters much like in a stored procedure. In T‑SQL:
EXEC sp_executesql N'SELECT mycol FROM dbo.tbl WHERE keycol = @value',
N'@value int', @value = @value
Or in C#:
cmd.CommandText = "SELECT mycol FROM dbo.tbl WHERE keycol = @value";
cmd.Parameters.Add("@value", SqlDbType.Int);
cmd.Parameters["@value"].Value = value;
The C# code results in a call to sp_executesql which looks exactly like the T‑SQL example above.
For more details on sp_executesql, please see my article The Curse and Blessings of Dynamic SQL.
Query plans for dynamic SQL are put into the plan cache, just like plans for stored procedures. (If you hear someone telling you something else, that person is either just confused or relying on very old information. Up to SQL Server 6.5, SQL Server did not cache plans for dynamic SQL.) As with stored procedures, plans for dynamic SQL may be flushed from the cache for a number of reasons, and individual statements may be recompiled. Furthermore, there may be more than one plan for the same query text because of differences in SET options.
Adding to that, there are a few more factors that can introduce puzzling behaviour with parameter sniffing that do not apply to stored procedures which we will look at in the next few sections.
When SQL Server looks up a stored procedure in the cache, it uses the name of the procedure. But that is not possible with a batch of dynamic SQL, as there is no name. Instead, SQL Server computes a hash from the query text and uses this hash as a key in the plan cache. And here is something very important: this hash value is computed without any normalisation whatsoever of the batch text. Comments are not stripped. White space is not trimmed or collapsed. Case is not forced to upper or lowercase, even if the database has a case-insensitive collation. The hash is computed from the text exactly as submitted, and any small difference will yield a different hash and a different cache entry. (There is one exception, that I will return to when we discuss auto-parameterisation.)
Run this with Include Actual Execution Plan enabled:
EXEC sp_executesql N'SELECT * FROM Orders WHERE OrderDate > @orderdate',
N'@orderdate datetime', '20000101'
EXEC sp_executesql N'SELECT * FROM Orders WHERE OrderDate > @orderdate',
N'@orderdate datetime', '19980101'
EXEC sp_executesql N'select * from Orders where OrderDate > @orderdate',
N'@orderdate datetime', '19980101'
You will find that the first two calls use the same plan, Index Seek + Key Lookup, whereas the third query uses a Clustered Index Scan. That is, the second call reuses the plan created for the first call. But in the third call, the SQL keywords are in lowercase. Therefore, there is no cache hit, and a new plan is created. Just to enforce this fact, here is a second example with the same result.
DBCC FREEPROCCACHE
go
EXEC sp_executesql N'SELECT * FROM Orders WHERE OrderDate > @orderdate',
N'@orderdate datetime', '20000101'
EXEC sp_executesql N'SELECT * FROM Orders WHERE OrderDate > @orderdate',
N'@orderdate datetime', '19980101'
EXEC sp_executesql N'SELECT * FROM Orders WHERE OrderDate > @orderdate ',
N'@orderdate datetime', '19980101'
The difference is that there is a single trailing space in the third statement.
There is one more thing to observe. If you run this query:
SELECT '|' + est.text + '|' FROM sys.dm_exec_query_stats qs CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) est WHERE est.text LIKE '%Orders%'
You will see this output:
|(@orderdate datetime)SELECT * FROM Orders WHERE OrderDate > @orderdate| |(@orderdate datetime)SELECT * FROM Orders WHERE OrderDate > @orderdate |
(The vertical bars serve to highlight the trailing space.) Notice here that the parameter list is also part of the query text, and it too is included in the query text that is hashed. Run this:
EXEC sp_executesql N'SELECT * FROM Orders WHERE OrderDate > @orderdate',
N'@orderdate datetime', '19980101'
That is, the same query again, but with one more space in the parameter list. If you now run the DMV query again, you will see that it now returns three rows. (Well, four since it also finds itself.)
This detail about the parameter list may seem like a thing of more trivial nature, but it has an important implication if you are writing client code. Consider this snippet of C#:
cmd.CommandText = "SELECT * FROM dbo.Orders WHERE CustomerID = @c";
cmd.Parameters.Add("@c", SqlDbType.NVarChar).Value = TextBox.Value;
Note that the parameter is added without a specific length for the parameter value. Say that the value in the text box is ALFKI. This results in the following call to SQL Server:
exec sp_executesql N'SELECT * FROM Orders WHERE CustomerID = @c',
N'@c nvarchar(5)',@c=N'ALFKI'
Note that the parameter is declared as nvarchar(5). That is, the length of the parameter is taken from the length of the actual value passed. This means that if you run the same batch multiple times with different parameter values of different length, you will get multiple cache entries. Not only do you litter the cache, but because of parameter sniffing, you can haphazardly get different plans for different parameter lengths. This can result in confusing behaviour where the same operation is slow for one value, but fast for another, although you would expect the same performance for these values.
There is a simple remedy for this particular problem: always specify the length explicitly:
cmd.Parameters.Add("@c", SqlDbType.NVarChar, 5).Value = TextBox.Value;
Here I used 5, since the CustomerID column is nchar(5). If you don't want to create a dependency to the data model, you can specify the length as something higher, for instance 4000 (which is the maximum for a regular nvarchar).
Another difference to stored procedures is less obvious, and is best shown with an example. Run this and look at the execution plans:
DBCC FREEPROCCACHE
go
CREATE SCHEMA Schema2
go
CREATE USER User1 WITHOUT LOGIN WITH DEFAULT_SCHEMA = dbo
CREATE USER User2 WITHOUT LOGIN WITH DEFAULT_SCHEMA = Schema2
GRANT SELECT ON Orders TO User1, User2
GRANT SHOWPLAN TO User1, User2
go
EXEC sp_executesql N'SELECT * FROM Orders WHERE OrderDate > @orderdate',
N'@orderdate datetime', '20000101'
go
EXECUTE AS USER = 'User1'
EXEC sp_executesql N'SELECT * FROM Orders WHERE OrderDate > @orderdate',
N'@orderdate datetime', '19980101'
REVERT
go
EXECUTE AS USER = 'User2'
EXEC sp_executesql N'SELECT * FROM Orders WHERE OrderDate > @orderdate',
N'@orderdate datetime', '19980101'
REVERT
go
DROP USER User1
DROP USER User2
DROP SCHEMA Schema2
go
The script first clears the plan cache and then creates a schema and two database users and grants them the permissions needed to run the queries. We then run the same query three times, but with different parameter values. The first time we pass a date which is beyond the range in Northwind, so the optimizer settles for a plan with Index Seek + Key Lookup. The second and third time we run the query, we pass a different date, for which a Clustered Index Scan is a better choice. But since there is a cached plan, we expect to get that plan, and that is also what happens in the second execution. However, in the third execution, we find to our surprise that the plan is the CI Scan. What is going on? Why did we not get the plan in the cache?
The key here is that we run the query as three different users. The first time we run the query as ourselves (presumably we are dbo), but for the other two executions we impersonate the two newly created users. (If you are not acquainted with impersonation, look up the topic for EXECUTE AS in Books Online; I also cover it in my article Packaging Permissions in Stored Procedures.) The users are login-less, but that is only because we don't need any logins for this example. What is important is that they have different default schemas. User1 has dbo as its default schema, but for User2 the default schema is Schema2. Why does this matter?
Keep in mind that when SQL Server looks up an object, it first looks in the default schema of the user, and if the object is not found, it looks in the dbo schema. For dbo and User1, the query is unambiguous, since dbo is its default schema and this is the schema for the Orders table. But for User2 this is different. Currently there is only dbo.Orders, but what if Schema2.Orders is added later? Per the rules, User2 should now get data from that table and not from dbo.Orders. But if User2 would use the same cache entry as dbo and User1, that would not happen. Therefore, User2 needs a cache entry of its own. If Schema2.Orders is added, that cache entry can be invalidated without affecting other users.
We can see this in the plan attributes. Here is a variation of the query we ran for stored procedures:
SELECT qs.plan_handle, a.attrlist
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.plan_handle) est
CROSS APPLY (SELECT epa.attribute + '=' + convert(nvarchar(127), epa.value) + ' '
FROM sys.dm_exec_plan_attributes(qs.plan_handle) epa
WHERE epa.is_cache_key = 1
ORDER BY epa.attribute
FOR XML PATH('')) AS a(attrlist)
WHERE a.attrlist LIKE '%dbid=' + ltrim(str(db_id())) + ' %'
AND est.text LIKE '%WHERE OrderDate > @orderdate%'
AND est.text NOT LIKE '%sys.dm_exec_plan_attributes%'
There are three differences to the query for stored procedures:
When I ran this query, I saw this (partial) list of attributes:
date_first=7 date_format=1 dbid=6 objectid=158662399 set_options=251 user_id=5
date_first=7 date_format=1 dbid=6 objectid=158662399 set_options=251 user_id=1
First look at objectid. As you see, this value is identical for the two entries. This object id is the hash value that I described above. Next, look at the attribute which is distinctive: user_id. The name as such is a misnomer; the value is the default schema for the users using this plan. The dbo schema always has schema_id = 1. In my Northwind database, Schema2 got schema_id = 5 when I ran the query, but you may see a different value.
Now run this query:
EXEC sp_executesql N'SELECT * FROM dbo.Orders WHERE OrderDate > @orderdate',
N'@orderdate datetime', '20000101'
And then run the query against sys.dm_exec_plan_attributes again. A third row in the output appears:
date_first=7 date_format=1 dbid=6 objectid=549443125 set_options=251 user_id=-2
objectid is different from above, since the query text is different. user_id is now -2. What does this mean? If you look closer at the query, you see that we now specify the schema explicitly when we access Orders. That is, the query is now unambiguous, and all users can use this cache entry. And that is exactly what user_id = -2 means: there are no ambiguous object references in the query. The corollary of this is that it is very much best practice to always use two-part notation in dynamic SQL, no matter whether you create the dynamic SQL in a client program or in a stored procedure.
This applies not only to tables and views, but also any user-defined functions you may call. It also applies to user-defined types that you may use (table types, CLR types, plain alias types etc) including the parameter list. (The parameter list is part of what is cached.) If a single object that lives in sys.objects or sys.types is referred to in one-part notation, this reference prevents the cache entry from being shared by users with different default schemas.
You may think "we don't use schemas in our app, so this is not an issue for us", but not so fast! When you use CREATE USER, the default schema for the new user is indeed dbo, unless you specify something else. However, if the DBA is of the old school, he may create users with any of the legacy procedures sp_adduser or sp_grantdbaccess, and they work differently. They do not only create a user, but they also create a schema with the same name as the user and set this schema as the default schema for the newly created user and make this user the owner of the schema. Does it sound corny? Yes, but up to SQL 2000, schema and users were unified in SQL Server. Since you may not have control over how users are created, you should not rely on users having dbo as their default schema.
Finally, you may wonder why this issue does not apply to the caching of plans for stored procedures. The answer is that in a stored procedure, the name resolution is performed from the schema of the procedure itself, not from the current user. That is, in a procedure in the dbo schema, Orders can only refer to dbo.Orders, never to any Orders table in some other schema. In a procedure in the schema OtherSchema, Orders first resolves to OtherSchema.Orders, and if there is no such table or view it resolves to dbo.Orders. Since this is the same for all users, it does not affect plan caching. (Keep in mind that this applies only to the direct query text of the stored procedure. It does not apply to dynamic SQL invoked with EXEC() or sp_executesql inside the procedure.)
I said that there is one exception to the rule that SQL Server does not normalise the query text before computing the hash. That exception is auto-parameterisation, a mechanism by which SQL Server replaces constants in an unparameterised query and makes it a parameterised query. The purpose of auto-parameterisation is to reduce the menace of poorly written applications that inline parameter values into SQL strings instead of conforming to best practice by using parameterised statements.
There are two models for auto-parameterisation: simple and forced. The model is controlled by a database setting, and simple parameterisation is the default. With this model, SQL Server auto-parameterises only SQL statements of very low complexity. Furthermore, SQL Server only employs simple auto-parameterisation when there is a single possible plan; that is, simple parameterisation is designed to not cause parameter-sniffing issues. However, as we shall see in a moment, the way this is implemented can cause some confusion, when you don't pay attention. With forced parameterisation, SQL Server replaces all constants in a query with parameters, even if multiple plans are possible. That is, when forced parameterisation is in play, you can face issues with parameter sniffing.
Note: Forced parameterisation only applies to dynamic SQL, never to queries in stored procedures. Furthermore, forced parameterisation is not applied to queries that refer to variables. There are a few more situations when SQL Server does not apply forced parameterisation, as listed in this topic in Books Online.
In the following, we shall look at how you can see whether you may have a parameter sniffing problem due to auto-parameterisation. The script below sets Northwind into forced parameterisation and then runs two queries against the Orders table. One that returns no rows, and one which returns the majority of the rows.
ALTER DATABASE Northwind SET PARAMETERIZATION FORCED
DBCC FREEPROCCACHE
go
SELECT * FROM Orders WHERE OrderDate > '20000101'
go
SELECT * FROM Orders WHERE OrderDate > '19970101'
go
; WITH basedata AS (
SELECT est.text AS sqltext, qp.query_plan,
charindex('<ParameterList>', qp.query_plan) + len('<ParameterList>')
AS paramstart,
charindex('</ParameterList>', qp.query_plan) AS paramend
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) est
CROSS APPLY sys.dm_exec_text_query_plan(qs.plan_handle,
qs.statement_start_offset,
qs.statement_end_offset) qp
WHERE est.text NOT LIKE '%exec_query_stats%'
), next_level AS (
SELECT sqltext, query_plan,
CASE WHEN paramend > paramstart
THEN CAST (substring(query_plan, paramstart,
paramend - paramstart) AS xml)
END AS params
FROM basedata
)
SELECT sqltext,
(SELECT CR.c.value('@Column', 'nvarchar(128)') + ' = ' +
CR.c.value('@ParameterCompiledValue', 'nvarchar(512)') + ' '
FROM n.params.nodes('ColumnReference') AS CR(c)
FOR XML PATH(''), TYPE).value('.', 'nvarchar(MAX)') AS Params,
CAST (query_plan AS xml) AS [Query plan]
FROM next_level n
go
If you look at the Execution Plan output in SSMS, you see this on the top:

That is, the date has been replaced by a parameter, @0. And if you look at the execution plans, you see that both queries run with Index Seek + Key Lookup, despite that the second query is best implemented as a Clustered Index Scan since it accesses the better part of the table. The output from the diagnostic query is like this:
![]()
That is, despite that we ran two statements with different query text, there is only one cache entry where the plan is determined from the date value in the first SELECT statement.
Now change FORCED in the script to read SIMPLE and run the script again. In the top of the execution plan, you see the same as above (except that @0 is now @1 for some reason). However, this time the two queries have different execution plans, and the output from the last query now looks like this:

At a casual glance, there may seem to be auto-parameterisation going on, but it is not the case. What seems to happen with simple parameterisation is that SQL Server attempts to auto-parameterise the query, but when it compiles the query it finds that there is more than one possible plan, and backs out of auto-parameterisation. However, some traces of the auto-parameterisation attempt remain, and this could lure you if you only look at the query text in the Showplan output. You need to get the text from sys.dm_exec_sql_text as in the query above, to see the actual text in the plan cache to be sure that auto-parameterisation is actually in play.
Note: When you run the above for simple parameterisation, you may see NULL in the columns Params and Query plan when you run the script the first time. If you rerun it, without including the first batch, you will see values on the second run. This is due to the configuration parameter optimize for ad hoc workloads. When this parameter is 1, SQL Server only caches the query text on the first execution of an unparameterised string. Only if the same string is executed a second time, the plan is cached. The default for this setting is 0, but 1 is the recommended setting, as it mitigates the effect of poorly written applications that do not parameterise statements. There are no known downsides with setting the option to 1. Starting with SQL 2019, this setting can also be enabled per database with ALTER DATABASE SCOPED CONFIGURATION.
As you understand from the previous sections, there are a few more pitfalls when you want to troubleshoot an application query from SSMS which may cause you to get a different cache entry, and potentially a different query plan.
As with stored procedures, you need to keep ARITHABORT and other SET options in mind. But you also need to make sure that you have exactly the same query text, and that your default schema agrees with the user running the application.
The latter is the easiest to deal with. In most cases this will do:
EXECUTE AS USER = 'appuser' go -- Run SQL here go REVERT
appuser is here the database user that the application uses – either a private user for the application, or the user name of the actual person using the database. Observe that this fails if the query accesses resources outside the current database. In this case you can use EXECUTE AS LOGIN instead. Note that this requires a server-level permission.
Retrieving the exact SQL text can be more difficult. The best is to use a trace to capture the SQL; you can run the trace either in Profiler or as a server-side trace. If the SQL statement is unparameterised, you need to be careful that you copy the full text, and then select exactly that text in SSMS. That is, do not drop or add any leading or trailing blanks. Don't add line breaks to make the query more readable, and don't delete any comments. Keep it exactly as the application runs it. You can use the query against sys.dm_exec_plan_attributes in this article to verify that you did not add a second entry to the cache.
Another alternative is to get the text from sys.dm_exec_query_stats and sys.dm_exec_sql_text. Here is a query you can use:
SELECT '<' + est.text + '>' FROM sys.dm_exec_query_stats qs CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) est WHERE est.text LIKE '%some significant SQL text here%'
When copying the text from SSMS, it is important to make sure that line breaks are retained. If you run the query in Text mode this is not a problem, but if you are in Grid mode, you need to be careful as by default SSMS replaces line breaks with spaces (which is good if you want to copy data to Excel, but not here). You can change this under Tools->Options as seen here:
Note that this option is not available in older versions of SSMS. If you have SSMS 2012 or SSMS 2014 it does not matter, as they retain CR/LF anyway. (But SSMS 2008 and SSMS 2005 do not.)
Parameterised SQL is easier to deal with, since the SQL statement is packaged in a character literal. That is, if you see this in Profiler
EXEC sp_executesql N'SELECT * FROM Orders WHERE OrderDate > @orderdate',
N'@orderdate datetime', '20000101'
It's no issue if you happen to change it to, say:
EXEC sp_executesql N'SELECT * FROM Orders WHERE OrderDate > @orderdate', N'@orderdate datetime', '20000101'
What is important is that you must not change anything of what is between the quotes of the two first parameters to sp_executesql, since this is what the hash is computed from. (That is, the parameter list is included in the hash computation.)
If you don't have any server-level permission – ALTER TRACE to run a trace, or VIEW SERVER (PERFORMANCE) STATE to query sys.dm_exec_query_stats and
sys.dm_exec_sql_text – it's starting to get difficult. (Unless you are on SQL 2016 or later and you have enabled Query Store for the database, which I will cover in the next chapter.) If the dynamic SQL is produced in a stored procedure which you can edit, you can add a PRINT statement to get the text. (Actually, stored procedures
that produce dynamic SQL should
always have a @debug parameter and include the line: IF @debug = 1 PRINT @sql.)
You still have to be careful to get the exact text, and not add or drop any spaces. If there is a parameter list, you need to make sure
that you
copy the parameter
list exactly as well. If the SQL is produced by the application, getting the SQL statement may be possible if you can run the application in a
debugger, but the exact text of the parameter list may be difficult to get at. The best bet may be to try the application against a database on an SQL
Server instance where you have all the required permissions, for instance on
your local workstation and get the query text this way.
Sometimes you may find that you want to modify a query to resolve a performance issue by adding a hint of some sort. For a stored procedure, it is not unlikely that you can edit the procedure and deploy the change fairly immediately. But if the query is generated inside an application, it may be more difficult. The entire executable has to be built and maybe be deployed to all user machines. It is also likely that there is a mandatory QA step involved. And if it is a third-party application, changing the code is out of the question.
However, SQL Server provides solutions for these situations. In this chapter, we will look at plan guides. Plan guides can be heaven-sent if you have a slow query in an application you cannot change. However, as you will find, they are not that easy to set up, and it is likely that you will only use plan guides as a last resort. There is a shortcut known as plan freezing which is easier to use. Nevertheless, plan freezing is something which is mainly of interest on SQL 2014 and earlier, as on SQL 2016 and later, you would use Query Store for the same task, and we will look at this in the next chapter.
Note: Plan guides are not available on the low-end editions of SQL Server – Express, Web and Workgroup Edition.
Here is an example of setting up a plan guide. This particular example runs on SQL 2008 and up:
DBCC FREEPROCCACHE
go
EXEC sp_executesql N'SELECT * FROM dbo.Orders WHERE OrderDate > @orderdate',
N'@orderdate datetime', @orderdate = '19960101'
go
EXEC sp_create_plan_guide
@name = N'MyGuide',
@stmt = N'SELECT * FROM dbo.Orders WHERE OrderDate > @orderdate',
@type = N'SQL',
@module_or_batch = NULL,
@params = N'@orderdate datetime',
@hints = N'OPTION (TABLE HINT (dbo.Orders , INDEX (OrderDate)))'
go
EXEC sp_executesql N'SELECT * FROM dbo.Orders WHERE OrderDate > @orderdate',
N'@orderdate datetime', @orderdate = '19980101'
go
EXEC sp_control_plan_guide N'DROP', N'MyGuide'
In this example, I create a plan to ensure that a query against OrderDate always uses an Index Seek (maybe because I expect all queries to be for the last few days or so). I specify a name for the guide. Next, I specify the exact statement for which the guide applies. As when you run a query in SSMS to investigate it, you need to make sure that you do not add or lose any leading or trailing space, nor must you make any other alteration. The parameter @type specifies that the guide is for dynamic SQL and not for a stored procedure. Had the SELECT statement been part of a larger batch, I would have to specify the text of that batch in the parameter @module_or_batch, again exactly as submitted from the application. When I specify NULL for @module_or_batch, @stmt is assumed to be the entire batch text. @params is the parameter list for the batch, and again there must be an exact match character-by-character with what the application submits.
Finally, @hints is where the fun is. In this example I specify that the query should always use the index on OrderDate, no matter the sniffed value for @orderdate. This particular query hint, OPTION (TABLE HINT) is not available in SQL 2005, which is why the example does not run on that version.
In the script, the initial DBCC FREEPROCCACHE is only there to give us a clean slate. Also, for the purpose of the demo, I run the query with a parameter value that gives the "bad" plan, the Clustered Index Scan. Once the plan guide has been entered, it takes effect immediately. That is, any current entry for the query is evicted from the cache.
On SQL 2008 and later, you can specify the parameters to sp_create_plan_guide in any order as long as you name them, and you can leave out the N before the string literals. However, SQL 2005 is far less forgiving. The parameters must be entered in the given order, even if you name them, and you must specify the N before all the string literals.
In this example I used a plan guide to force an index, but you can use other hints as well, including the USE PLAN hint that permits you to specify the complete query plan to use. Certainly not for the faint of heart!
...although that is exactly the idea with plan freezing. Say that you have a query that sways between two plans, one good and one bad, due to parameter sniffing, and there is not really any civilised way to get the bad plan out of the equation. Rather than battling with the complex parameters of sp_create_plan_guide, you can extract a plan handle from the cache and feed it to the stored procedure sp_create_plan_guide_from_handle to force the plan you know is good. Here is a demo and example.
DBCC FREEPROCCACHE
SET ARITHABORT ON
go
EXEC sp_executesql N'SELECT * FROM dbo.Orders WHERE OrderDate > @orderdate',
N'@orderdate datetime', @orderdate = '19990101'
go
DECLARE @plan_handle varbinary(64),
@rowc int
SELECT @plan_handle = plan_handle
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) est
WHERE est.text LIKE '%Orders WHERE OrderDate%'
AND est.text NOT LIKE '%dm_exec_query_stats%'
SELECT @rowc = @@rowcount
IF @rowc = 1
EXEC sp_create_plan_guide_from_handle 'MyFrozenPlan', @plan_handle
ELSE
RAISERROR('%d plans found in plan cache. Cannot create plan guide', 16, 1, @rowc)
go
-- Test it out!
SET ARITHABORT OFF
go
EXEC sp_executesql N'SELECT * FROM dbo.Orders WHERE OrderDate > @orderdate',
N'@orderdate datetime', @orderdate = '19960101'
go
SET ARITHABORT ON
EXEC sp_control_plan_guide 'DROP', 'MyFrozenPlan'
For the purpose of the demo, I first clear the plan cache and set ARITHABORT to a known state. Then I run my query with a parameter that I know will give me the good plan. The next batch demonstrates how to use sp_create_plan_guide_from_handle. I first run a query against sys.dm_exec_query_stats and sys.dm_exec_sql_text to find the entry for my query. Next, I capture @@rowcount into a local variable (since @@rowcount is set after each statement, I prefer to copy it to a local variable in a SELECT that is directly attached to the query to avoid accidents). This is a safety precaution in case I get multiple matches or no matches in the cache. If I get exactly one match, I call sp_create_plan_guide_from_handle which takes two parameters: the name of the plan guide and the plan handle. And that's it!
The next part tests the guide. To make sure that I don't use the same cache entry, I use a different setting of ARITHABORT. If you run the demo with display of execution plan enabled, you will see that the second execution of the query uses the same plan with Index Seek + Key Lookup as the first, although the normal plan for the given parameter would be a Clustered Index Scan. That is, the plan guide is not tied to a certain set of plan attributes.
When you use this for real, you would run the query you want the plan guide for, only if the desired plan is not in the cache already. The query against the cache will require some craftsmanship so that you get exactly one hit and the correct hit. An alternative may be to look at the matches in the query output in SSMS and copy and paste the plan handle.
A cool thing is that you don't have to set this up on the production server, but you can experiment on a lab server. The guide is stored in sys.plan_guides, so once you have the guide right, you can use the content there to craft a call to sp_create_plan_guide that you run the production server. You can also script the plan guide through Object Explorer in SSMS.
There is one consideration about forcing plans when it comes to temp tables that I learnt from Marshall Smith. He told me that in his company when they forced a plan with a plan guide, the plan guide was not always obeyed. They found that these queries involved temp tables with unnamed PRIMARY KEY constraints. When you add constraints on temp tables, you should never name them, because if you do, you will get a collision if two parallel processes create the same temp table. Instead, you should let SQL Server generate the names for the constraints. But this proved to have a by-effect with plan guides. Because the index name was new each time, the optimizer was not always able to match the plan guide with the query. I tried to repro this myself with a quick example, but in my case the plan guide was matched. I guess this is because when matching a plan guide there is some fuzzy margin, but if the query is complex enough, the matching may nevertheless fail.
The way that Marshall's team solved the issue was to use a named index instead. That is, rather than saying
CREATE TABLE #temp (id int NOT NULL PRIMARY KEY,
data varchar(100) NULL)
they changed this to:
CREATE TABLE #temp (id int NOT NULL,
data varchar(100) NULL,
INDEX ix CLUSTERED (id)
)
Because the name space for non-constraint indexes is per table, there is no risk for collision between parallel processes here. This syntax for CREATE TABLE was introduced in SQL 2014.
If you have a multi-statement batch or a stored procedure, you may not want to set up a guide for the entire batch, but only for a statement. For this reason, sp_create_plan_guide_from_handle accepts a third parameter @statement_start_offset, a value you can get from sys.dm_exec_query_stats.
One potential problem with plan guides is that since they don't appear in the query text, they can easily be overlooked and forgotten. One risk is that as the database evolves, the plan mandated by the plan guide is no longer the best one. The profile of the data could have changed, or a better index could have been added. A second risk is that the query is changed in some seemingly innocent way. But if the text changes, if so only by adding a single space, the plan guide will no longer match, and you may be back to the original poor performance, and having forgotten all about the plan guide, you will have to reinvent the wheel.
For this reason, it is a good idea to add to your troubleshooting checklist that you should query sys.plan_guides to see if there are any plan guides at all in the database, and if there is you can further investigate whether they are relevant to the queries you are battling. If you want to see the currently active plan guides, you can also use this query to find this information in the plan cache:
; WITH constants AS (
SELECT N' PlanGuideDB="' AS guide_db_attr, guide_name_attr = N'PlanGuideName="'
), basedata AS (
SELECT est.text AS sqltext, qp.query_plan,
charindex(c.guide_db_attr, qp.query_plan) + len(c.guide_db_attr)
AS guide_db_start,
charindex(c.guide_name_attr, qp.query_plan) + len(c.guide_name_attr)
AS guide_name_start
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) est
CROSS APPLY sys.dm_exec_text_query_plan(qs.plan_handle,
qs.statement_start_offset,
qs.statement_end_offset) qp
CROSS JOIN constants c
WHERE est.text NOT LIKE '%exec_query_stats%'
), next_level AS (
SELECT sqltext, query_plan,
CASE WHEN guide_db_start > 100
THEN substring(query_plan, guide_db_start,
charindex('"', query_plan, guide_db_start + 1) -
guide_db_start)
END AS PlanGuideDB,
CASE WHEN guide_name_start > 100
THEN substring(query_plan, guide_name_start,
charindex('"', query_plan, guide_name_start + 1) -
guide_name_start)
END AS PlanGuideName
FROM basedata
)
SELECT sqltext, PlanGuideName, PlanGuideDB,
TRY_CAST (query_plan AS xml) AS [Query plan]
FROM next_level n
WHERE PlanGuideDB IS NOT NULL OR PlanGuideName IS NOT NULL
The query is similar in nature to the queries we have used to extract parameter values from the plan, but here we are looking for the two attributes that identify the plan guide. The normal way to extract them would be to use XQuery, but as I have remarked: there is a risk that the plan cannot be represented in the built-in xml data type, hence the acrobatics with charindex and substring.
To learn more about plan guides, see the sections on plan guides in Books Online or the white paper listed in the section Further Reading below.
Query Store first appeared in 2016. When Query Store is enabled for a database, SQL Server saves the plans, the settings and execution statistics for queries in persisted tables. The Query Store tables are not exposed directly. Instead you query views that also include data that has not yet been persisted to disk. (To ensure that Query Store has a low overhead, data is flushed to disk tables asynchronously.)
Query Store permits you to track query execution over time and when abrupt change in performance occurs because a plan changed from one day to another, you can go and find both plans in the Query Store tables. And, if you need to address the problem quickly, you can force the old and faster plan.
This chapter does not aim at giving a full coverage of Query Store, but only to give you queries to get the same information from Query Store as I have previously shown for the plan cache. If you have the choice of getting plans from Query Store and the plan cache, Query Store is often a better alternative since data is persisted. For instance, say that users reported bad performance between nine and ten in the morning, but at the time you got to investigate the issue, performance was back to normal, because the query with the bad plan was recompiled for some reason without your intervention. In this case, you cannot find the plan in the cache so that you can investigate how the plan looked like and what parameter values it was sniffed for. On the other hand, chances are good that you can find the bad plan in the Query Store tables.
Since Query Store is on database level, this gives you an advantage if you are looking for problems in a specific database – no need to filter out other databases. But this cuts both ways; if you are looking for issues on a server-wide basis, you may prefer to query the plan cache. The fact that Query Store is on database level, gives a second advantage if you do not have server-level permissions: you only need the permission VIEW DATABASE STATE to run queries against the Query Store tables. (You have this permission, if you are a member of the db_owner role).
As I mentioned, Query Store was introduced in SQL 2016, and it has evolved in every version of SQL Server since then. And Query Store is not merely an aide for the performance tuner, but other recent performance-related features in SQL Server relies on Query Store to persist information. As a result of this, the defaults for Query Store have changed between the versions. Here are the most important settings by version:
Note that these default settings apply to newly created databases. If you restore a database from SQL 2019 which did not have Query Store turned on an instance running SQL 2022, Query Store will remain disabled until you turn it on. The same applies to the other settings.
The default max size is how much size you permit the Query Store tables to take up. If this size is exceeded, Query Store will put itself into read-only mode. You should give Query Store enough space to hold the data for 30 days, which is the default retention period for Query Store. (This default is the same for all SQL Server versions.) This default often works. When you first enable Query Store, you need to monitor the size consumption to find out what max size that is appropriate for your workload. You can review the size consumption and the settings (including if the Query Store is in read-only mode) in sys.database_query_store_options.
The setting QUERY_CAPTURE_MODE controls exactly which query executions Query Store collects information for. ALL means exactly that: each and every execution. We will use this setting in this article, to be sure that the labs work. However, this setting is not recommendable in production. If you have a workload that produces many short small unparameterised queries, setting QUERY_CAPTURE_MODE to ALL could take the server over the brink. With the setting AUTO, Query Store only stores information about queries in dynamic SQL that exceed certain thresholds. (Queries in stored procedures are always captured). This setting is a better choice for casual use of Query Store, but if you want to engage in more advanced performance tuning, you may prefer ALL. Starting with SQL 2019, there is a CUSTOM mode that allows you to set your own thresholds. One situation you would consider doing this is when you find that even with AUTO, Query Store adds too much overhead. In this case, you could try raising the thresholds.
Beside the settings I have discussed here, there are a few more settings that I am not covering, but which you occasionally have to look into. I refer you to the topic for ALTER DATABASE in Books Online for details.
For the labs we will do in this chapter, we need Query Store to be enabled for Northwind with capture more ALL, so run this:
ALTER DATABASE Northwind SET QUERY_STORE = ON (QUERY_CAPTURE_MODE = ALL)
The first query against the plan cache we looked at is one that gives us the plan attributes that are cache keys. The Query Store version of this query is a lot more straightforward, since the plan attributes are accessed through sys.query_context_settings where each attribute is a column. The SET options are still a bit mask, though. Here is a query that returns the most important plan attributes:
SELECT q.query_id, convert(bigint, cs.set_options) as set_options,
cs.language_id, cs.date_format, cs.date_first, cs.default_schema_id
FROM sys.query_store_query q
JOIN sys.query_context_settings cs
ON q.context_settings_id = cs.context_settings_id
WHERE q.object_id = object_id('dbo.List_orders_6')
The test case for this query was:
CREATE PROCEDURE List_orders_6 AS SELECT * FROM Orders WHERE OrderDate > '12/01/1998' go SET DATEFORMAT dmy go EXEC List_orders_6 go SET DATEFORMAT mdy go EXEC List_orders_6 go
When I ran the query above, I got this output:
query_id set_options language_id date_format date_first default_schema_id
-------- ----------- ----------- ----------- ---------- -----------------
7 4347 0 2 7 -2
8 4347 0 1 7 -2
Note that there are different values in the column date_format. When it comes to the column query_id, this is only an internal ID for the query and you may see different values when you try the above. However, you may note that while the query text is the same, different settings result in different query_ids.
We can use Query Store to find which parameter values a plan was sniffed for. This query is slightly simpler than the same query against the plan cache, because we don't have to dabble with the offsets to get the query text. But the query still has to count as complex, because we need to do the same work to extract the parameter values from the plan XML:
; WITH basedata AS (
SELECT q.query_text_id, q.context_settings_id, p.query_plan, qt.query_sql_text,
last_compile_batch_offset_start / 2 AS stmt_start,
charindex('<ParameterList>', p.query_plan) + len('<ParameterList>')
AS paramstart,
charindex('</ParameterList>', p.query_plan) AS paramend
FROM sys.query_store_query q
JOIN sys.query_store_plan p ON q.query_id = p.query_id
JOIN sys.query_store_query_text qt ON q.query_text_id = qt.query_text_id
WHERE q.object_id = object_id('dbo.List_orders_11')
), next_level AS (
SELECT query_text_id, context_settings_id, query_plan, query_sql_text, stmt_start,
CASE WHEN paramend > paramstart
THEN TRY_CAST(substring(query_plan, paramstart,
paramend - paramstart) AS xml)
END AS params
FROM basedata
)
SELECT convert(bigint, cs.set_options) AS [SET], stmt_start AS Pos,
n.query_sql_text AS Statement,
CR.c.value('@Column', 'nvarchar(128)') AS Parameter,
CR.c.value('@ParameterCompiledValue', 'nvarchar(128)') AS [Sniffed Value],
TRY_CAST (query_plan AS xml) AS [Query plan]
FROM next_level n
CROSS APPLY n.params.nodes('ColumnReference') AS CR(c)
JOIN sys.query_context_settings cs
ON n.context_settings_id = cs.context_settings_id
ORDER BY [SET], Pos, Parameter
The query starts with sys.query_store_query, which is the main Query Store table that defines the query and here we can filter on the object id for the procedure we are interested in. The query text is taken from sys.query_store_query_text, while the query plan is in sys.query_store_plan. Just like in sys.dm_exec_text_query_plan the XML for the plan is stored in a nvarchar(MAX) column due to limitation in the xml data type. We handle the XML exactly in the same way as in the original query. In the final SELECT, I get the SET options from sys.query_context_settings.
This was the test case we used earlier:
SET ARITHABORT ON EXEC List_orders_11 '19980101', 'ALFKI' go SET ARITHABORT OFF EXEC List_orders_11 '19970101', 'BERGS'
The output from the query above is similar to the output to the original query earlier in the article, but you will find that the query text also includes the parameter list.
If you want to find the parameters for a batch of dynamic SQL, you need to replace this condition in the CTE basedata
WHERE q.object_id = object_id('dbo.List_orders_11')
with a condition on some suitable piece in the query text. You may also want to filter out the query against Query Store itself. Thus, you may get something like:
WHERE qt.query_sql_text LIKE '%Orderdate >%' AND qt.query_sql_text NOT LIKE '%query_store_query%'
If you have a query that for some reason gets recompiled frequently and occasionally gets a bad plan due to sniffing, the query above may return many rows. To reduce the noise you can use the views sys.query_store_runtime_stats and sys.query_store_runtime_stats_interval to filter the result. Say that users in the New Delhi office reported that they had bad performance between 09:00 and 10:00, their local time. You can add this condition to the CTE basedata above:
AND EXISTS (SELECT *
FROM sys.query_store_runtime_stats rs
JOIN sys.query_store_runtime_stats_interval rsi
ON rs.runtime_stats_interval_id = rsi.runtime_stats_interval_id
WHERE rs.plan_id = p.plan_id
AND rsi.end_time >= '20161125 09:00 +05:30'
AND rsi.start_time <= '20161125 10:00 +05:30')
The gist here is that Query Store saves run-time statistics for a plan by intervals. A row in sys.query_store_runtime_stats holds the statistics for a plan during an interval, and sys.query_store_runtime_stats_interval holds the duration for such an interval. You should observe that the data type of the columns start_time and end_time is datetimeoffset, which is why I have included the TZ offset in the queries above. Note that if you leave out the TZ offset, your values will be converted to UTC (offset +00:00) and you may not find the data you are looking for.
Instead of filtering on time, you can filter on one of the many columns in sys.query_store_runtime_stats to select only plans with a certain resource consumption. This is left as an exercise for the reader.
As I mentioned, you can use Query Store to force a plan. This is akin to plan guides, but when you force a plan through Query Store, this does not result in an entry in sys.plan_guides. There is also a difference to how this works with different cache keys. This script illustrates:
ALTER DATABASE Northwind SET QUERY_STORE CLEAR
SET ARITHABORT ON
go
EXEC sp_executesql N'SELECT * FROM dbo.Orders WHERE OrderDate > @orderdate',
N'@orderdate datetime', @orderdate = '19990101'
go
DECLARE @query_id bigint,
@plan_id bigint,
@rowc int
SELECT @query_id = q.query_id, @plan_id = p.plan_id
FROM sys.query_store_query q
JOIN sys.query_store_plan p ON q.query_id = p.query_id
JOIN sys.query_store_query_text qt ON q.query_text_id = qt.query_text_id
WHERE qt.query_sql_text LIKE '%Orders WHERE OrderDate%'
AND qt.query_sql_text NOT LIKE '%query_store_query%'
SELECT @rowc = @@rowcount
IF @rowc = 1
EXEC sp_query_store_force_plan @query_id, @plan_id
ELSE
RAISERROR('%d rows found in Query Store. Cannot force plan', 16, 1, @rowc)
SET ARITHABORT OFF
EXEC sp_executesql N'SELECT * FROM dbo.Orders WHERE OrderDate > @orderdate',
N'@orderdate datetime', @orderdate = '19960101'
SET ARITHABORT ON
EXEC sp_executesql N'SELECT * FROM dbo.Orders WHERE OrderDate > @orderdate',
N'@orderdate datetime', @orderdate = '19960101'
SELECT q.query_id, p.plan_id, p.is_forced_plan,
convert(bigint, cs.set_options) as set_options,
qt.query_sql_text, try_cast(p.query_plan AS xml)
FROM sys.query_store_query q
JOIN sys.query_store_query_text qt ON q.query_text_id = qt.query_text_id
JOIN sys.query_store_plan p ON q.query_id = p.query_id
JOIN sys.query_context_settings cs
ON q.context_settings_id = cs.context_settings_id
WHERE qt.query_sql_text LIKE '%Orders WHERE OrderDate%'
AND qt.query_sql_text NOT LIKE '%query_store_query%'
EXEC sp_query_store_unforce_plan @query_id, @plan_id
For the purpose of the demo, I clear the Query Store tables. I then run a query against the Orders database for which Index Seek + Key Lookup is the best plan with the given parameters. Next, I retrieve the query and plan ids for this query. The check on @@rowcount is only to make sure that the demo runs as expected. Following this, I force this plan with sp_query_store_force_plan. Next, I run the query again twice, once with ARITHABORT OFF and once with ARITHABORT ON. Note that this time, I specify parameter values so that all orders will be returned and thus the best plan is a Clustered Index Scan.
If you look at the plans for the latter two queries, you will find that the first execution with ARITHABORT OFF uses the CI Scan, that is, the forced plan is not considered, whereas the second execution indeed uses the forced plan. Thus, when you force a plan with Query Store, you only force it for a particular set of cache keys. This is different to when we froze a plan with sp_create_plan_guide_from_handle; in that case the forced plan was applied also when ARITHBORT was OFF.
This is followed by a diagnostic query. Before we look at the output, we can note that it is very simple to find whether there are plans that have been forced through Query Store: there is a column is_forced_plan in sys.query_store_plan. However, if we look at the output from the query, it is maybe not as you would expect. (For space reasons, I don't include the last two columns):
query_id plan_id is_forced_plan set_options count_executions
----------- --------- -------------- -------------- --------------------
4 4 0 251 1
1 1 1 4347 1
1 5 0 4347 1
There are three rows in the output, not one, despite that we ran the same query three times. As we learnt before, the context settings (or plan attributes) are tied to the query_id. Whence, the execution with set_options = 251 (ARITHABORT OFF) has a different query_id. And since we force the plan for a specific query_id, this explains why the Seek + Lookup was not enforced for ARITHABORT OFF.
Remains to understand why there are two entries for query_id = 1. We can guess that the one with plan_id = 5 comes from the second execution, since presumably plan_id is assigned sequentially from 1 after clearing Query Store. But why is there a new plan, when we forced plan_id = 1? When I forced the plan, the plan fell out of cache, since Query Store does not check whether I'm forcing the current plan or an older plan. For this reason, there was a new compilation when the query was re-executed with ARITHABORT ON. When a plan is forced, SQL Server does not just take that plan at face value, since it may not be a usable plan. (For instance, it could refer to an index that has been dropped.) Instead, the optimizer generates plans until it has generated the forced plan – or a plan which is very similar to the original plan.
If you save the XML for the plans to disk, you can use your favourite compare tool to compare them. I used Beyond Compare, and this is an excerpt of what I saw for plan_id = 5:
I have highlighted the pertinent differences. First note the appearance of the attribute UsePlan="1" which is absent from plan_id 1. This indicates that the plan is indeed a forced plan. (Through Query Store, a plan guide or explicit use of the USE PLAN hint.) What is also interesting is the appearance of the attribute WithUnorderedPrefetch which is not present in the plan actually forced. That is, this plan has a different implementation of the Nested Loop Join operator from the original plan and it also has a column reference which is not in the first plan. That is, plans 1 and 5 are not exactly the same. Or more generally, when you force a plan, you may not get exactly the same plan as the one you forced, but you will get a plan – as a Microsoft developer described it to me – that is morally equivalent to the original plan.
Generally, I recommend that you use plan forcing in Query Store over plan guides, as this is easier to use than plan guides. However, the same caveats apply. Over the years, as data changes, the forced plan may no longer be the best choice. For a long-term solution it is often better to tune queries, add indexes etc. However, forcing a plan can be a quick short-term solution to solve an urgent performance problem.
In the section on plan guides, I related an observation from Marshall Smith that it may help to use named indexes in temp tables, rather than unnamed PRIMARY KEY constraints for plan guides to match. It seems likely this observation also applies to forcing plans through Query Store as well.
While forcing plans from Query Store is easier than forcing plans through plan guides, the observant reader may realise that there is a gap. What if you want to inject a hint to lead the optimizer in the right direction, rather than forcing the full plan? If you are on SQL 2019 or earlier, you will still have to resort to plan guides. However, in SQL 2022, Microsoft introduced Query Store hints, so that we can set hints through Query Store with help of the stored procedure sp_query_store_set_hints. You provide the query ID and the hints you want to set. Here is an example. In the first step, we only create the hint:
USE Northwind
go
ALTER DATABASE Northwind SET QUERY_STORE CLEAR
DBCC FREEPROCCACHE
SET ARITHABORT ON
go
EXEC sp_executesql N'SELECT * FROM dbo.Orders WHERE OrderDate > @orderdate',
N'@orderdate datetime', @orderdate = '19990101'
go
DECLARE @query_id bigint,
@plan_id bigint,
@rowc int
SELECT @query_id = q.query_id, @plan_id = p.plan_id
FROM sys.query_store_query q
JOIN sys.query_store_plan p ON q.query_id = p.query_id
JOIN sys.query_store_query_text qt ON q.query_text_id = qt.query_text_id
WHERE qt.query_sql_text LIKE '%Orders WHERE OrderDate%'
AND qt.query_sql_text NOT LIKE '%query_store_query%'
SELECT @rowc = @@rowcount
IF @rowc = 1
BEGIN
EXEC sp_set_session_context N'QueryID', @query_id
EXEC sp_query_store_set_hints
@query_id = @query_id,
@query_hints = N'OPTION (OPTIMIZE FOR UNKNOWN)'
END
ELSE
RAISERROR('%d rows found in Query Store. Cannot force plan', 16, 1, @rowc)
I start with clearing Query Store and the plan cache for demo purposes. There is an example query. and as the date is outside the range for the orders in Northwind, the plan is an Index Seek + Key Lookup. Next, I retrieve the query ID for the query in the same manner as in the previous section. I save the query ID in session context, so that I can retrieve it in a later batch. Then comes the call to sp_query_store_set_hints. I provide the query ID and the hints. For clarity, I'm using parameter names, but beware that the parameter names are blissfully ignored. The procedure requires that the parameters come in this exact order.
You may recall that when we did the same exercise with plan guides that I forced an index with TABLE HINT. However, that particular hint is not available (yet) with sp_query_store_set_hints. Instead, I'm using OPTIMIZE FOR UNKNOWN which we can expect to lead to a Clustered Index Scan, since the default estimate is a 30 % hit rate. So let's test this by running the query again:
EXEC sp_executesql N'SELECT * FROM dbo.Orders WHERE OrderDate > @orderdate',
N'@orderdate datetime', @orderdate = '19990101'
Indeed, this time we got a scan, so the hint worked.
Note this:
SET ARITHABORT OFF
go
EXEC sp_executesql N'SELECT * FROM dbo.Orders WHERE OrderDate > @orderdate',
N'@orderdate datetime', @orderdate = '19990101'
Just like when we force a plan through Query Store, a Query Store hint only has effect for the specific SET options in sys.query_context_settings tied to the query id we provide.
You can review current query hints with this query:
SELECT * FROM sys.query_store_query_hints
As I indicated above, there are some limitations on which hints you can set. I don't want to include a list of supported and unsupported hints here, since this list could change over time. Instead I refer you to the online documentation for sp_query_store_set_hints.
Before we leave this section, let's remove the query hint:
DECLARE @query_id int = cast(SESSION_CONTEXT(N'QueryID') AS int) EXEC sp_query_store_clear_hints @query_id
Before I leave the topic of Query Store, I should add that there is a GUI for Query Store in SQL Server Management Studio where you can investigate which are the expensive queries etc, and you can also force plans from this UI. I leave it to the reader to explore these options on your own.
If you want to learn more about Query Store, you can read the topic Monitoring Performance By Using the Query Store in Books Online. For a longer, more in-depth discussion, you may be interested in a series of articles on Query Store by Data Platform MVP Enrico van der Laar published on Simple Talk.
As I said earlier in the article, the problem is not really with parameter sniffing as such, but with parameter-sensitive queries, or if you will, parameter-sensitive plans, PSP for short. In SQL 2022, Microsoft introduced what they call PSP optimisation, which is available in all editions of SQL Server, including Express Edition. If you read their marketing material casually, you may be led to believe that Microsoft has fixed the problems with parameter sniffing once for all. However, as I will discuss in this chapter this is not really the case. There are some important limitations, and it is also a little bit too simple-minded to really be a game changer. Occasionally, it will save the day for a few people out there, but most of the time, you will have to deal with performance issues related to parameter-sensitive queries, and thus parameter sniffing, on SQL 2022 as well.
I have labelled this as an appendix, because I don't think this material is equally essential as the rest of the article. If you feel that your brain is hurting enough already, feel free to jump to the Concluding Remarks for some links for further reading. But if you want to know some more details about PSP optimisation, hang on.
The first limitation to observe is that PSP optimisation applies only to equi-predicates, that is, predicates using the equal (=) operator. Most of the examples we have looked at so far have been inequality predicates with >, <= etc. Now, admittedly, an important reason for this is that it made it very easy for me to set up simple demo examples in the Northwind database. But you may recall the section The Case of the Application Cache where I related a real-world case where the challenge was exactly with inequality predicates. That is not to say that you cannot get parameter-sniffing problems with equi-predicates too – you may recall the example with fruits, I think that one specific, and fairly common scenario that Microsoft might have had in mind is a multi-tenant application, where all tenants are in the same table, and where the size of the business of the various tenants can vary vividly.
You should be aware that PSP optimisation is only active if the compatibility level is 160 or higher. (This is always the case when Microsoft introduces optimizer enhancements; they are not available for older compatibility levels.) Also observe that on compatibility level 160, PSP optimisation only applies to pure SELECT queries. It does not apply to INSERT, UPDATE, DELETE, MERGE or even SELECT INTO. If you are on compatibility level 170 (i.e. SQL 2025), there is no such restriction.
Let's now have a look at this feature in practice. Since Northwind does not have any suitable table, we will create a new database for this section and set up a demo table.
DROP TABLE IF EXISTS PSPTest
CREATE TABLE PSPTest (id int NOT NULL PRIMARY KEY,
skewed int NOT NULL INDEX skew_ix,
numdata float NOT NULL,
moredata char(200) NOT NULL DEFAULT ' '
)
go
INSERT PSPTest(id, skewed, numdata)
SELECT value, CASE WHEN abs(crypt_gen_random(4) % 1000) < 500 THEN 4801
ELSE abs(crypt_gen_random(4) % 10000)
END,
rand(crypt_gen_random(2))
FROM generate_series(1, 1000000)
Note: if you get an error about the generate_series function, verify that you actually are on SQL 2022 and that the compatibility level of the database is 160. generate_series is a new function in SQL 2022.
The script generates one million rows, with 10000 different values in the column skewed. For about half of the rows, skewed is 4801, while the remaining 9999 values are evenly distributed. You can confirm this by running this query:
SELECT skewed, COUNT(*) AS cnt FROM PSPTest GROUP BY skewed ORDER BY cnt DESC
We will now create a very simple procedure:
CREATE OR ALTER PROCEDURE PSPdemo @par int AS SELECT SUM(numdata) FROM dbo.PSPTest WHERE skewed = @par
Before we run it, we can note for most values of @par, the best plan is an Index Seek on the index on skewed combined with a Key Lookup. But if @par is 4801, a Clustered Index Scan is a better choice. Let's now try this:
EXEC PSPdemo 24 EXEC PSPdemo 4801
Indeed, we get two different places. Here is the plan for the first call:

Exactly the Index Seek we wanted! And the other plan is that CI Scan – and with parallelism as well:

If you look into the XML of the plan, you will find something that is new to SQL 2022:
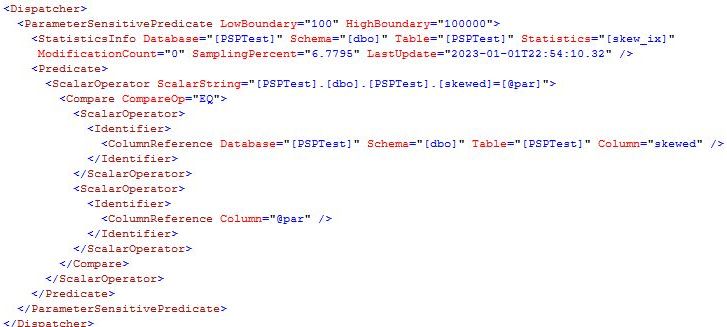
When you see this Dispatcher element in a plan, you know that PSP optimisation has kicked in. The dispatcher defines three bins for the parameter from the LowBoundary and HighBoundary attributes. Into which bin a parameter value goes depends on the estimate the optimizer computes from the histogram. If the estimated number of rows is below LowBoundary (100 in this example), the value goes into the first bin. If the estimate falls between the two boundaries, it falls into the second bin, and if the estimate is beyond HighBoundary (100000 in this case), the value falls into the third bin.
From these bins, SQL Server defines Query Variants. In this particular example, there can be up to three variants. (A variant is only defined if there actually is a value that falls into the corresponding bin.) For a more complex query where there are several predicates on highly-skewed columns, there can be as many as 27 variants. That is, SQL Server can select up to three parameters for which it defines bins, resulting in 3×3×3 possible variants.
It may be easier to understand how this works, if we look into the plan cache. Here is a query that retrieves all plans with a Dispatcher element.
WITH XMLNAMESPACES (
'http://schemas.microsoft.com/sqlserver/2004/07/showplan' as ns1
)
SELECT s.name AS "Schema", o.name AS "Name", qp.query_plan, est.text
FROM sys.dm_exec_cached_plans AS cp
CROSS APPLY sys.dm_exec_query_plan(cp.plan_handle) AS qp
CROSS APPLY sys.dm_exec_sql_text(cp.plan_handle) AS est
LEFT JOIN (sys.objects o
JOIN sys.schemas s ON o.schema_id = s.schema_id)
ON est.objectid = o.object_id
WHERE qp.dbid = db_id()
AND qp.query_plan.exist('/ns1:ShowPlanXML/ns1:BatchSequence/
ns1:Batch/ns1:Statements/ns1:StmtSimple/ns1:Dispatcher') = 1
You may note that this query does not go against sys.dm_exec_query_stats, but instead queries sys.dm_exec_cached_plans. In sys.dm_exec_query_stats, we have information sliced down to each individual statement in the batch, but in sys.dm_exec_cached_plans, we have information for the entire cache entry, which is the full batch or stored procedure. It will be apparent later why I'm using this DMV here. Likewise, I am retrieving the query plan with sys.dm_exec_query_plan, which gives us the execution plan for the entire batch.
Note: since the query returns the full execution plan and the full text for the stored procedures it finds, it can return large amounts of data, if you have long stored procedures with several thousands of lines of code. If you only want to see which procedures that have one or more dispatcher plans, let it suffice with the Schema and Name columns.
This how the result from the query looks like:

You may note that we get three rows back. The last row is apparently the statement in the stored procedure. But what are the other two rows? Let's look at the text column in full:
(@par int)SELECT SUM(numdata) FROM dbo.PSPTest WHERE skewed = @par
option (PLAN PER VALUE(ObjectID = 949578421, QueryVariantID = 3,
predicate_range([PSPTest].[dbo].[PSPTest].[skewed] = @par, 100.0, 100000.0)))
(@par int)SELECT SUM(numdata) FROM dbo.PSPTest WHERE skewed = @par
option (PLAN PER VALUE(ObjectID = 949578421, QueryVariantID = 1,
predicate_range([PSPTest].[dbo].[PSPTest].[skewed] = @par, 100.0, 100000.0)))
This looks like a parameterised query that has been submitted through sp_executesql, and we can recognise that this is the query from the PSPdemo procedure. Tacked on to the query is a query hint that you are likely not to have seen before. And, no, it is not a hint you can use yourself, but it is something that works only inside the engine. You may note that the two query strings are almost identical. The sole difference is the value for QueryVariantID.
You may have already figured out what is going on. The dispatcher results in dynamic child queries being created, and because of the difference in query text, they will result in different cache entries and therefore they can have different execution plans. You may ask what is the exact meaning of the PLAN PER VALUE hint. This is nothing I have researched. Maybe the hint only serves to produce different query texts. But maybe the optimizer is able to take advantage of that for QueryVariantID 1, there will never be a value of @par with an estimated hit rate of more than 100 rows.
You can also look for dispatcher plans in sys.dm_excec_query_stats, but there is a difference. Here is a query:
WITH XMLNAMESPACES (
'http://schemas.microsoft.com/sqlserver/2004/07/showplan' as ns1
)
SELECT cast(tqp.query_plan AS xml) AS stmt_query_plan,
substring(est.text, qs.statement_start_offset/2 + 1,
iif (qs.statement_end_offset > qs.statement_start_offset,
(qs.statement_end_offset - qs.statement_start_offset) / 2 + 1,
len(est.text))) AS stmttext, est.objectid,
qs.*
FROM sys.dm_exec_query_stats AS qs
CROSS APPLY sys.dm_exec_query_plan(qs.plan_handle) AS qp
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) AS est
OUTER APPLY sys.dm_exec_text_query_plan(qs.plan_handle,
qs.statement_start_offset, qs.statement_end_offset) AS tqp
WHERE qp.dbid = db_id()
AND qp.query_plan.exist('/ns1:ShowPlanXML/ns1:BatchSequence/
ns1:Batch/ns1:Statements/ns1:StmtSimple/ns1:Dispatcher') = 1
This query only returns the two rows for the child queries, but the parent statement in the stored procedure does not appear. This is because this statement is never executed directly, and therefore it does not assemble any statistics. Only the child queries have execution statistics.
You may ask how the boundaries for these bins are selected. This is a Microsoft trade secret, but if you are keen on it, you can do some experimenting and see what observations you can make. But I like to briefly discuss what is not going on. If we take this example, there are two competing plans, the Index Seek + Key Lookup which is good for parameters that match a smaller number of rows, and the Clustered Index Scan which is a better choice when the hit rate is higher. Between the extremes, there is a balance point at some mid-level cardinality for which the two alternatives yield the same performance. At first glance, it may seem ideal to select this balance point as a boundary, and with the simple nature of this query, there is only a need for two variants.
However, if we give it more thought, we realise that this is not a feasible approach. Imagine a query with 10-15 tables, and for which there are umpteen possible plans. Producing all these plans to compute balance points to determine the optimal bin boundaries would keep the optimizer busy for the rest of day. Keep in mind that such an operation would be more complicated than a normal compilation which is for one single value; to determine balance points they would have to run the compilation for many values.
So while I don't know exactly how they do it, it is clear that there is an element of guesswork here. If we look at our simple PSPdemo procedure, we can feel confident that for all values that lead to query variant 1, the Index Seek will be the right choice. Likewise, for all values that end up in the bin for query variant 3 the Clustered Index Scan is the winner.
Now, what about those in the middle? Because of the simple-minded way I have set up PSPTest, there are no values that fall into the middle bin. But imagine that there had been values in a more or less contiguous range of a cardinality between 100 and 100000? Do you think the same plan is good for that entire range?
That was intended to be a rhetorical question, but in case of disbelievers, let's run a test. We don't have the data to test with an equi-predicate. But this query serves very well as a substitute:
SELECT COUNT(*), SUM(numdata) FROM PSPTest WHERE skewed < 500
This query returns around 25000 rows, and the optimizer makes about the same estimate. The resulting plan is a Clustered Index Scan. Change 500 to 50, and the number of rows and the estimate falls to 2500. And the plan is now an Index Seek + Key Lookup.
The plan for that second bin will be one or the other, but that plan will not be good for all values in that bin. Which plan you get depends on which value that first falls into the bin, and for the values in the opposite side of the range for the bin, the plan will not be good. Or in other words: there will be a parameter-sniffing problem. But admittedly, the effect is likely to be smaller than without PSP optimisation, since for the values in the outermost bins, where an incorrect choice of plans has the highest impact, you get the correct plans.
There is one more observation to make. Run this:
UPDATE STATISTICS PSPTest skew_ix WITH FULLSCAN EXEC sp_recompile PSPdemo EXEC PSPdemo 24 EXEC PSPdemo 4801
Both executions now run with Index Seek + Key Lookup, and if you look at the execution plan, there is no Dispatcher element anymore. What happened? Previously, we had sampled statistics (because autostats kicked in when we ran the first call to PSPdemo). Now we have FULLSCAN statistics which are supposed to be more accurate. Why would that disqualify the query from PSP optimisation?
No, FULLSCAN as such has nothing to do with it. Rather it seems that the PSPTest table straddles on the border where the optimizer considers it worth the effort to employ PSP optimisation at all. The only input available for the optimizer to make this decision is the histogram. And by chance, with the sampled statistics the query qualifies, but with the FULLSCAN statistics it does not. And as such, this is alright. There has to be a boundary for where the optimizer considers it worthwhile to employ PSP optimisation. And when there is no exact knowledge to base this decision on, only statistics, be they sampled or fullscan, there will be queries for which PSP optimisation will come and go.
What does raise my eyebrow is that I think PSPTest is seriously skewed with one single value out of 10000 accounting for 50 % of the rows. I would like to believe that it is well beyond the border area. This observation makes me think that if the threshold for PSP optimisation to kick in is this high, there are many situations where parameter sniffing gives you a problem, where PSP optimisation will not be considered. (By the way, if you think that I worked hard to find this boundary area, this is not the case. The setup for PSPTest was more or less my first attempt to try out PSP optimisation, when I first got access to an SQL Server 2022 CTP.)
I like to highlight one thing on the practical side. If you run any of the queries against the plan cache above, you will find that the child queries are still there. Above, I only requested recompilation of the store procedures, but the child queries are not part of the procedure, but rather sub-procedures. As they will not be executed anymore, they will fall out of the cache, but that may take some time. Thus, if you find plans with Dispatcher elements, you need to find a query without the PLAN PER VALUE hint to conclude that PSP optimisation currently is in force.
Rather than looking in the plan cache, you can also use Query Store to see if you have any queries that are or have been subject to PSP optimisation. I am not going into details here, but I should mention that there is a new Query Store view sys.query_store_query_variant which links the parent query with the dynamic child queries produced by the dispatchers.
As with about all new optimizer features, it is possible to turn off PSP optimisation with a database-scoped configuration. But I see little reason to do this. While I'm kind of lukewarm about this feature, I can't see that it will be detrimental in any way. No, I am sure that there will be situations where PSP optimisation kicks in and saves our day, and we may not even notice that it happened. But I don't expect this to occur that often. At least not in SQL 2022. Microsoft may enhance this feature in a future release.
This appendix covers yet a cause to why you may find yourself in the situation Slow in the application, fast in SSMS. There are two reasons why I have put this scenario at the end of the article: 1) The explanation requires us to dive into advanced features of SQL Server that we did not have to look into in the rest of the article. 2) I have a feeling that this may not be something that occurs very often. This feeling is based on the fact that while I did run into this problem myself (and I was very confused before I understood what was going on), that happened many years after I had published the first version of this article.
In this appendix, we will first look at two confusing puzzles, and after these I will explain the reasons for the outcome. I will close the appendix with some remarks, including how you would typically address this problem.
First a setup. This script creates a table where there is a column which has unique values for the main bulk of the rows, but for around 10 % of the rows, the value is 0. Thus, there is a skew. There is a non-clustered index on this column.
DROP TABLE IF EXISTS skewed
CREATE TABLE skewed (id int NOT NULL,
semikey int NOT NULL,
data char(36) NOT NULL,
CONSTRAINT pk_skewed PRIMARY KEY (id)
)
INSERT skewed (id, semikey, data)
SELECT value, IIF(value % 10 = 0, 0, value), convert(char(36), newid())
FROM generate_series(1, 100000)
CREATE INDEX semikey_ix ON skewed(semikey)
To this, we add a stored procedure which accepts a comma-separated list of semikey values. The procedure reads this list into a temp table before running a query with OPTION (RECOMPILE).
CREATE OR ALTER PROCEDURE skew_sp @vals varchar(MAX) AS
CREATE TABLE #vals(val int NOT NULL PRIMARY KEY)
INSERT #vals(val)
SELECT value FROM string_split(@vals, ',')
SELECT MIN(data)
FROM skewed
WHERE semikey IN (SELECT val FROM #vals)
OPTION (RECOMPILE)
The thinking here is that OPTION(RECOMPILE) will help us to get in an optimal plan for the actual values passed to the procedure.
At this point, enable display of the actual execution plan in SSMS. Let's first pretend that we run this procedure from an application, that is, with ARITHABORT OFF:
SET ARITHABORT OFF EXEC skew_sp '67,879,99999'
This is the execution plan I get (because of size constraints, I have left out the leftmost SELECT operator):

The plan looks like the one we want. There is an Index Seek to find the three rows in skewed followed by a Key Lookup.
Now we call the procedure from SSMS, that is, with ARITHABORT ON.
SET ARITHABORT ON EXEC skew_sp '0'
This time, we send in one single value,but that is 0, so we will hit a lot more rows in the table, and the Index Seek + Key Lookup is no longer the best strategy. And indeed, we see a different plan:

The skewed table is now scanned from start to end.
We go back to the application, that is ARITHABORT OFF, and now we send in '0' here as well:
SET ARITHABORT OFF EXEC skew_sp '0'
We expect to see the same plan as directly above, that is a Clustered Index Scan of skewed. But no:

It is the same plan as when we sent in a list of unique values. It is just that the arrows are thicker, since a lot more rows are being processed. There is OPTION(RECOMPILE), so it is not a matter of a cached plan. And we have learnt that ARITHABORT has absolutely no effect (as long as ANSI_WARNINGS is on). Yet we get different plans with ON and OFF. How can this happen?
The first puzzle is a grossly simplified version of the situation I found myself in. Before we look at the explanation, we will look at a variation that is no less confusing. This puzzle is something I was able to compose once I had gathered a good understanding of my original problem.
We change the procedure to add a WAITFOR statement (which serves to facilitate the demo), and then we run the procedure with the three unique values:
CREATE OR ALTER PROCEDURE skew_sp @vals varchar(MAX) AS
WAITFOR DELAY '00:00:00.100'
CREATE TABLE #vals(val int NOT NULL PRIMARY KEY)
INSERT #vals(val)
SELECT value FROM string_split(@vals, ',')
SELECT MIN(data)
FROM skewed
WHERE semikey IN (SELECT val FROM #vals)
OPTION (RECOMPILE)
go
SET ARITHABORT OFF
EXEC skew_sp '67,879,99999'
After this, we take an exclusive application lock on session level:
EXEC sp_getapplock 'Start!', N'Exclusive', N'Session'
Next, open two query windows and enable Actual Execution Plan in both windows. Then paste this code into both windows:
EXEC sp_getapplock 'Start!', 'Shared', 'Session' SET ARITHABORT OFF EXEC skew_sp '0' EXEC sp_releaseapplock 'Start!', 'Session'
The code first tries to get a shared lock on session level on the Start! resource, but this will be blocked by the lock you took in the first window. Once the application lock becomes available, the code will run skew_sp with "application" settings, the same as we used initially. The parameter is '0', which matches many rows in the skewed table. Finally, the batch releases the application lock to clean up. The interesting point here is that the two windows will run skew_sp in parallel. (The purpose of the WAITFOR is to ensure that this really happens, else the scheduling could cause one window to complete before the other starts.)
In both windows, press the Execute button and verify that the windows do not complete, but are left in the Executing state. Now go to the first window and release the application lock:
EXEC sp_releaseapplock N'Start!', N'Session'
The other two windows now complete their execution. Go to these windows and look at the execution plans. If the demo worked as intended, you will find that the two windows have different execution plans. One has the plan with Index Seek + Key Lookup and one has the plan with the Clustered Index Scan of the skewed table. How can this be? If you look at the plan with the Index Seek, there is a clue in the details of the Index Seek operator:

There is a gross mis-estimate: The optimizer thinks that the Seek will hit one row, but it hits 10000 rows. On the other hand, in the plan with the CI scan, the estimates are correct throughout the plan. The incorrect estimate explains the choice of the plan with the Index Seek + Key Lookup, but where do the estimates come from? And why do the windows have different estimates?
The answer for the mysteries we have seen is due to how caching of temp tables works in SQL Server. You may have heard of this feature, as it has been in the product since SQL 2005. SQL Server caches the definition of temporary tables to avoid contention on the system tables in tempdb in systems where temporary tables are created with a very high level of concurrency. But there are some details about temp-table caching that are less known.
The first small detail is how the cache as such works: When a temp table that has been created in a stored procedure (or a trigger) is dropped logically, either explicitly with DROP TABLE or because the procedure exits, all rows with metadata about the temp table in the system tables are retained, with one single change: the name changes from its real name to be # followed by eight hex digits (which is the hex representation of the object id). If you run a SELECT against tempdb.sys.tables on a production server, you may see quite a few of these.
Note: There are some operations on temp tables that prevent caching. One example is creating an index after the CREATE TABLE statement. Only temp tables created in stored procedures and triggers are cached; those on top level and in dynamic SQL are not. Thus, this issue only applies to stored procedures and triggers.
The next important thing is that a cache entry of a temp table is tied to an execution context. A query plan is a template for how to run a stored procedure. An execution context is an instantiation of that template. A plan is re-entrant, and can be used by many processes simultaneously, but an execution context can only be used by one process at a time. The execution context is where you find the current values of local variables, the name of the current user, and other values unique to that process. And this includes temp tables. The cached temp table is not a template – it is one single physical table that can only be used by one process at a time, as per the definition of local temp tables. Thus, when two processes in parallel run the same procedure that creates the same logical temp table, there will be two execution contexts and two physical tables, and this is what happened in the second puzzle.
These execution contexts are not thrown away after execution. Instead, just like query plans, they are cached and reused. The restriction that only one process at a time can use an execution context remains. If the query plan leaves the cache, so does the execution contexts derived from it and the cached temp tables are dropped.
Now, consider the case when there are multiple plans with different cache keys for the same stored procedure. Can the same cached temp table be used by execution contexts of either plan? The answer is no. As I said, the execution context is an instantiation of a specific plan. Furthermore, there are some SET options that are saved with the temp table, for instance ANSI_PADDING, so the temp table could behave differently in different plans.
Thus, a difference in SET options or other cache keys will always lead to different physical temp tables. And if you look carefully in the first three query plans in the beginning of this appendix you can see this. Here I have extracted the Clustered Index Scan operators on the temp tables in the three plans to highlight an important detail:

The temp table itself is given as only #vals. But we can see the system-generated name of the primary-key constraint which reveals that we have different physical tables. The name of the PK is the same in the first and the last plan, which both have ARITHABORT OFF, whereas in the plan in the middle – the one with ARITHABORT ON – the PK has a different name.
We are getting closer to a solution to the initial puzzle, but there is still one piece missing. We know now that in the first and last invocation of skew_sp, where ARITHABORT was OFF, the same physical temp table was used. But that still does not explain why the plan with Index Seek + Key Lookup was used for the skewed table rather than the more efficient Clustered Index Scan in the last execution. Since there is OPTION (RECOMPILE), it is not a matter of reusing a cached plan. Yet, the compilation led to the same result. Why?
As I explained earlier, the cache is simply the rows in the system tables that are retained. What I did not mention, but which brings us very close to the solution, is that the cache also includes the statistics for the table. This is not directly evident from the plan operators above, since all three operators have the correct cardinality. This is because the cardinality is always (more or less) kept up to date. However, all other parts of the statistics, histogram, density etc are only updated occasionally – either when auto-update of the statistics is triggered, or when there is an explicit UPDATE STATISTICS command.
To get a final understanding of the puzzle, we need to learn a little about when statistics are auto-updated, and I will simply explain this by discussing what happens on the three invocations of skew_sp. First we ran:
SET ARITHABORT OFF EXEC skew_sp '67,879,99999'
When the execution arrived at the statement
SELECT MIN(data) FROM skewed WHERE semikey IN (SELECT val FROM #vals) OPTION (RECOMPILE)
SQL Server found that there was no statistics on #vals, and therefore SQL Server collected statistics for the temp table before it compiled the query. It could see that the values in #vals seemed to match very few rows in skewed, leading to the choice of the plan with the Index Seek + Key Lookup.
Next we ran:
SET ARITHABORT ON EXEC skew_sp '0'
As we have learnt, we got a new physical table representing our logical table #vals. Again, there were no statistics, so SQL Server ran autostats, and this time it could see that a Clustered Index Scan of skewed was the best choice.
And finally we ran:
SET ARITHABORT OFF EXEC skew_sp '0'
This time when we arrived the query with SELECT MIN, SQL Server found there were statistics on #vals and and proceeded to check if the number of modifications to the val column exceeded the recompilation threshold. For reasons we will learn in a second, it found that the answer was negative, and therefore SQL Server compiled the query with the old statistics from the previous execution.
To view this modification counter, you can modify skew_sp to include a DMV query that shows information about statistics:
CREATE OR ALTER PROCEDURE skew_sp @vals varchar(MAX) AS
WAITFOR DELAY '00:00:00.100'
CREATE TABLE #vals(val int NOT NULL PRIMARY KEY)
INSERT #vals(val)
SELECT value FROM string_split(@vals, ',')
SELECT *
FROM tempdb.sys.dm_db_stats_properties(object_id('tempdb..#vals'), 1)
SELECT MIN(data)
FROM skewed
WHERE semikey IN (SELECT val FROM #vals)
OPTION (RECOMPILE)
go
-- Initial run to set statistics.
SET ARITHABORT OFF
EXEC skew_sp '67,879,99999'
If you keep running
SET ARITHABORT OFF EXEC skew_sp '0'
You will see that the modification_counter increases, and when it reaches the recompilation threshold, autostats is triggered, and you will now get the plan with the Clustered Index Scan. For a small temp table with less than six rows, the recompilation threshold is six, so it will not take long before you see the change. If there are six rows up to 500 rows in the table, the threshold is 500, which means for a temp table with some 10-20 rows, it can take quite a few executions until autostats sets in. As you may guess, the more rows there are in the table, the higher the threshold.
Before I leave this section, I should say that parts of this explanation is based on my observations rather than reading documentation. I have also intentionally glossed over the finer details to keep the explanation reasonably simple. Thus, there may be smaller inaccuracies.
While we have seen the puzzles and acquired an understanding of the behaviour, there are still a few questions to discuss, not the least how to deal with the situation when we encounter it.
But before that, let's look at the fact that the statistics for a temp table are retained as part of the cache. This is not entirely intuitive, but is it an intentional design? Or is it something that just happened? I don't know, but I think that you can argue both ways. On the one hand, we are inclined to think that, logically, the temp table is empty when the procedure starts, and when we fill it up with data we expect autostats to set in and produce statistics from that data. On the other hand, if users tend to fill up the temp table in about the same fashion, it makes sense to retain the statistics, so that there is less autostats and compilation. Actually, that is not at all very different from regular parameter sniffing. And as with parameter sniffing, it may sometimes serve us well, and sometimes not.
In the puzzles, I used OPTION (RECOMPILE), and when I ran into this in real life that was also a query with OPTION (RECOMPILE). Does this mean that the effect of temp-table caching is only seen with OPTION (RECOMPILE)? No, if you go back and run the first puzzle without OPTION (RECOMPILE), you will get the same results as before. I only used OPTION(RECOMPILE) to highlight that it was not a matter of a cached plan. But as soon as there are differences in cache keys, this can happen to you, because you have different temp tables with different statistics.
Now, say that we are working with a performance problem, and we identify that the reason for Slow in the application, fast in SSMS is that the plan used by the application is using statistics that does not reflect the actual data in a temp table, because the statistics come from an earlier execution with a different profile. How can we address this problem? Many of the approaches I have discussed earlier in the article apply here as well. But there is one particular action that can remove the problem entirely: add UPDATE STATISTICS on the temp table in question before the problematic query. However, as I learnt from Paul White's blog post Temporary Table Caching in Stored Procedures, this is not sufficient: You also need OPTION (RECOMPILE) as the UPDATE STATISTICS alone will not trigger recompilation. (By the way, Paul White's article is also good reading, if you want to learn details about caching of temp tables that I don't cover here. He also covers more details on recompilation thresholds.)
It is worth pointing out that if you recreate the procedure the problem may seem to go away. But that is only because when you recreate the procedure, the existing query plans and execution contexts are dropped. And so are the cached temp tables, with their statistics.
What about the second puzzle? Is this something that can happen in real life as well? Two processes using the same cache entry for a stored procedure, get different query plans because there are different physical temp tables with different statistics? The puzzle itself was something I set up to illustrate the significance of the execution context, and I have not encountered this in the wild – as far as I know, that is. But I see no reason why you could not run into this situation and bring you into a state of confusion. You are running a stored procedure from the same place with the same parameters repeatedly, but you get very different performance because SQL Server picks different execution contexts with different physical temp tables. Although, I think this case, OPTION (RECOMPILE) is a precondition to get this puzzling behaviour. Because without OPTION (RECOMPILE), all execution contexts use the same query plan. If recompilation occurs in one of the execution contexts, the other execution contexts will see the new plan for the statement in later executions.
Finally, I am deeply indebted to my friend and MVP colleague Hugo Kornelis. As I mentioned, I ran into this puzzle myself, and it made me very confounded. I reached out for help in an internal forum where MVPs and people from the Product Group hang out, and I shared my query plans. Hugo spent quite a bit of time analysing these plans, and he made some findings that were very valuable to me. Not only did they help me to solve my original tuning problem, but his observations made me realise that cached temp tables are tied to the execution context and apply to a specific set of cache keys, which was the piece I was missing to solve the puzzle. He was also kind to point out the flaws in my first attempt for a demo.
You have now learnt why a query may perform differently in the application and in SSMS. You have also seen several ways to address issues with parameter sniffing.
Did I include all reasons why there could be a performance difference between the application and SSMS? Not all, there are certainly a few more reasons. For instance, if the application runs on a remote machine, and you run SSMS directly on the server, a slow network can make quite a difference. But I believe I have captured the most likely reasons that are due to circumstances within SQL Server.
Did I include all possible reasons why parameter sniffing may give you a bad plan, and how you should address it? Probably not. There is room for more variation there, and particularly I can't know what your application is doing. But hopefully some of the methods I have presented here can help you to find a solution.
If you think that you have stumbled on something which is not covered in the article, but you think I should have included, please drop me a line at esquel@sommarskog.se. And the same applies if you see any errors in the article, not the least spelling or grammar errors. On the other hand, if you have a question about how to solve a particular problem, I recommend you to post a question to an SQL Server forum, because a lot more people will see your question. If you want me to see the question, your best chances are to post to Microsoft Learn Q&A forum using the tag SQL Server Database Engine.
If you want to learn more about query compilation, statistics etc, below are a few articles that I like to recommend. You may note that they all relate to old versions of SQL Server. This is because I assembled the article list when I wrote the first version of this article. I have not investigated whether there are newer versions of these articles. But even if you are on a newer version of SQL Server, the articles are still largely applicable, although there have been some improvements which are not covered by these articles.
Statistics Used by the Query Optimizer in Microsoft SQL Server 2008 – A white paper written by Eric Hanson and Yavor Angelov from the SQL Server team.
Plan Caching in SQL Server 2012 – A white paper written by SQL Server MVP Greg Low. Appendix A in this paper details the rules for simple parameterisation.
Troubleshooting Performance Problems in SQL Server 2008 – An extensive document, which looks at performance from several angles, not only query tuning. Written by a number of developers and CSS people from Microsoft.
Forcing Query Plans – A white paper about plan guides. This version is for SQL 2005; I have not seen any version for SQL 2008.